
- 분류 전체보기 (418)

- Python (37)
- Machine Learning (95)
- Statistical Learning (55)
- Time Series Analysis (13)
- Natural Language Processing (31)
- Data Visualization & DataBa.. (16)
- Recommendation System (9)
- Feature Engineering (11)
- Explainable AI (11)
- GCP (23)
- DevOps (30)
- Web (23)
- Growth Hacking (3)
- Mathematics (3)
- Hadoop (4)
- Frontend (1)
- Computer Science (36)
- Papers (10)
- Etc. (3)
250x250
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- TensorFlow
- Airflow
- UDF
- hadoop
- XAI
- top_k
- chatGPT
- requests
- Retry
- session 유지
- API
- integrated gradient
- API Gateway
- youtube data
- tensorflow text
- 상관관계
- flask
- login crawling
- gather_nd
- GenericGBQException
- airflow subdag
- grad-cam
- GCP
- Counterfactual Explanations
- subdag
- spark udf
- BigQuery
- 유튜브 API
- correlation
- 공분산
Archives
- Today
- Total
데이터과학 삼학년
[크롤링] 로그인 후 게시판 목차의 링크를 받아와(n page 까지의 게시물 전체 링크) website 크롤링 본문
Natural Language Processing
[크롤링] 로그인 후 게시판 목차의 링크를 받아와(n page 까지의 게시물 전체 링크) website 크롤링
Dan-k 2020. 9. 10. 21:09반응형
크롤링을 위해 web 사이트 로그인 후
게시판 목록의 url 링크를 검색한후
모아진 url을 이용해 크롤링하는 코드를 올린다
로그인은 저번 게시물에서 확인할 수 있다
목차의 링크를 받기 위해
목차 페이지에 들어가 목차가 어느 소스에 href로 매칭되어 있는지 확인한다.
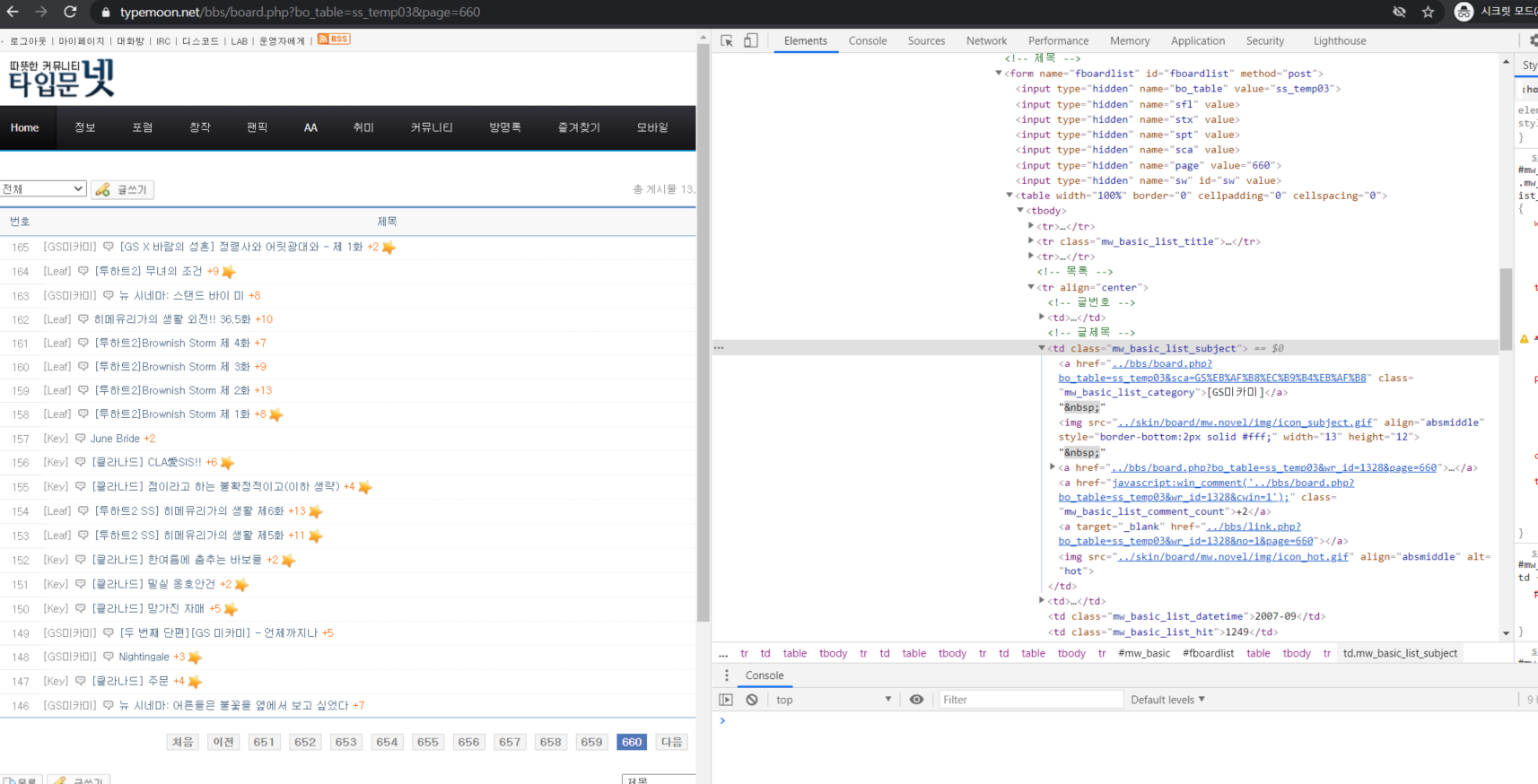
확인이 어려울 경우,
'a' 검색후 모든 'href'를 받아온후 re 를 이용해 얻길 원하는 패턴의 url을 뽑는 방법도 있다.
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import re
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('/home/bdh/chromedriver',chrome_options=chrome_options)
driver.implicitly_wait(3)
### 로그인
driver.get('https://www.typemoon.net/bbs/login.php')
login_x_path='/html/body/table/tbody/tr/td/table[2]/tbody/tr/td/table/tbody/tr/td/form/table/tbody/tr[4]/td[2]/table/tbody/tr/td/table/tbody/tr[1]/td[2]/input'
driver.find_element_by_name('mb_id').send_keys('<유저 id>')
driver.find_element_by_name('mb_password').send_keys('<유저 passwords>')
driver.find_element_by_xpath(login_x_path).click()
### 목차의 url을 모두 받아오자
def get_wr_id(txt):
p = re.compile('../bbs............................................')
txt = p.findall(txt)
result = txt[0].split('&')[-2].split('=')[-1]
return result
def make_link(page_url):
response = driver.get(page_url)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
link_lst = []
for link in soup.find_all('a'):
link_lst.append(link.get('href'))
contents_lst = []
for ind, link_data in enumerate(link_lst):
if '../bbs/board.php?bo_table=ss_temp03&wr_id=' in str(link_data) :
contents_lst.append(link_data)
wr_id_set= set()
for link in contents_lst:
wr_id_set.add(get_wr_id(link))
url_link =[]
for i in list(wr_id_set):
url_link.append('https://www.typemoon.net/bbs/board.php?bo_table=ss_temp03&wr_id={}'.format(str(i)))
return url_link
def get_url_links(page_url_sample,N_page):
url_links_lst = []
for i in range(1,N_page+1):
page_url = page_url_sample.format(str(i))
url_links = make_link(page_url)
url_links_lst += url_links
return url_links_lst
page_url_sample = 'https://www.typemoon.net/bbs/board.php?bo_table=ss_temp03&page={}'
N_page = 3
url_links = get_url_links(page_url_sample,N_page)
len(url_links)
## 61 --> 1~3페이지 까지의 url_links : 61
## 받은 url_links를 이용해 crawling
def remove_html_tags(data):
p = re.compile(r'<.*?>')
return p.sub(' ', str(data))
def get_crawl(URL):
response = driver.get(URL)
html = driver.page_source
soup7 = BeautifulSoup(html, 'html.parser')
ex_id_divs = soup7.find('div', {'id': 'view_content'})
crawl_data = remove_html_tags(ex_id_divs)
return crawl_data
for i, url in enumerate(url_links):
try :
data = get_crawl(url)
df = pd.DataFrame([{'story': 'story_test_{}'.format(str(i)),
'episode':'story_test_{}'.format(str(i)),
'contents': data,
'label': 1,
'language_code':'KOR'}])
except:
continue
if i == 0 :
new_data = df.copy()
else:
new_data = pd.concat([new_data, df],axis=0)
print(new_data.shape)
new_data.tail()

728x90
반응형
LIST
'Natural Language Processing' 카테고리의 다른 글
| 텔레그램 챗 내용 export 및 parser (feat. beautifulsoup) (0) | 2022.04.19 |
|---|---|
| 텔레그램봇을 활용한 유저 채팅 데이터 수집 및 활용(feat. telepot, telegram) (2) | 2022.03.24 |
| [크롤링] 로그인이 필요한 website 크롤링 (2) | 2020.09.09 |
| [번역 API] Google translate를 이용한 언어 번역 API 사용 (0) | 2020.09.08 |
| Transfer learning 적용 정리 : universal sentence encoder multilingual (0) | 2020.08.10 |
'Natural Language Processing' Related Articles
more



Comments