
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- GCP
- XAI
- Airflow
- top_k
- gather_nd
- integrated gradient
- 유튜브 API
- Counterfactual Explanations
- login crawling
- GenericGBQException
- UDF
- airflow subdag
- hadoop
- subdag
- requests
- chatGPT
- 공분산
- API
- session 유지
- TensorFlow
- API Gateway
- BigQuery
- flask
- Retry
- spark udf
- 상관관계
- tensorflow text
- correlation
- youtube data
- grad-cam
- Today
- Total
데이터과학 삼학년
[크롤링] 로그인이 필요한 website 크롤링 본문
사실 크롤링은 웹 html 구조만 잘 알고 있으면, chrome에서 F12를 통해 웬만한 데이터는 다 뽑아 올 수있다.
주로 크롤링을 위해 사용하는 라이브러리는
-
requests
-
web url에 접근하고, html을 받아오는 용도
-
-
urlib
-
web url에 접근하고, html을 받아오는 용도
-
-
selenium
-
web url에 접근하고, html을 받아오는 용도
-
chrome driver를 이용하여 실제 마우스를 이용한 웹서핑을 가능하게 함
-
-
bs4 (BeautifulSoup)
-
web url로 부터 받아온 html text를 parser 하여 원하는 정보를 찾을 수 있도록 도움
-
등이다
로그인을 위해서 requests의 post나 urllib 의 쿠키를 유지하는 방식으로 로그인을 한 이후 (session 유지) 원하는 페이지에 들어가 crawling을 할 수 도 있지만.
보다 직관적인 방법으로 chromedriver를 이용해 chrom창을 띄우고, 직접 login페이지에 들어가고, login 버튼 클릭까지 코드로 진행할 수 있는 selenium을 통한 방식을 알아본다
먼저 크롤링을 하기 원하는 페이지에 들어가서 login 페이지 url을 찾는다.
www.typemoon.net/bbs/login.php
로그인 페이지에서 f12를 눌러 id란과 password란에 name 값을 알아온다.
mb_id, mb_password로 되어 있다
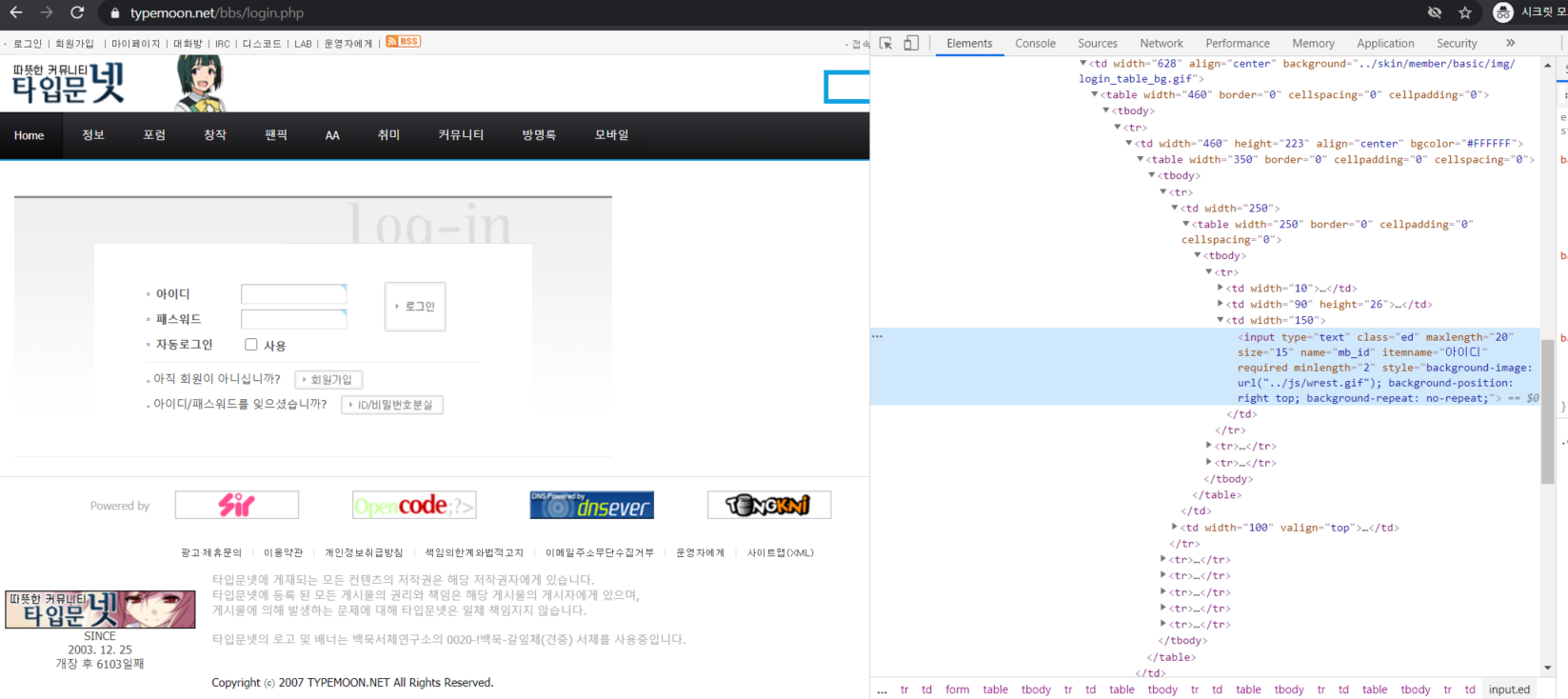
그리고 로그인 클릭 값을 위해 로그인 버튼의 x_path를 copy한다

이 두가지를 준비하면 로그인 준비는 끝!
이제 코드로 고고
1. 먼저 필요한 라이브러리를 import
여기서 chrome 드라이버를 환경에 맞게 다운후 불러와야 한다
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import re
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('/home/bdh/chromedriver',chrome_options=chrome_options)2. parsing을 위한 함수를 생성한다
- html tags들을 제거하는 것과 crawling하기 원하는 부분을 BeautifiulSoup을 통해 지정해준다.
def remove_html_tags(data):
p = re.compile(r'<.*?>')
return p.sub(' ', str(data))
def get_crawl(URL):
response = driver.get(URL)
html = driver.page_source
soup7 = BeautifulSoup(html, 'html.parser')
ex_id_divs = soup7.find('div', {'id': 'view_content'})
crawl_data = remove_html_tags(ex_id_divs)
return crawl_data3. 로그인
앞서 말했던 대로 login 클릭을 위한 x_path와 id, password를 통해 로그인한다
driver.implicitly_wait(3)
driver.get('https://www.typemoon.net/bbs/login.php')
login_x_path='/html/body/table/tbody/tr/td/table[2]/tbody/tr/td/table/tbody/tr/td/form/table/tbody/tr[4]/td[2]/table/tbody/tr/td/table/tbody/tr[1]/td[2]/input'
driver.find_element_by_name('mb_id').send_keys('<유저 id>')
driver.find_element_by_name('mb_password').send_keys('<유저 passwords>')
driver.find_element_by_xpath(login_x_path).click()4. 웹 크롤링
로그인이 되었으면 원하는 페이지에 가서 크롤링을 한다
url_sample = 'https://www.typemoon.net/bbs/board.php?bo_table=ss_temp01&wr_id={}' #193447 ~ 223457
for i in range(193447,223457):
try :
url = url_sample.format(str(i))
data = get_crawl(url)
df = pd.DataFrame([{'story': 'story_test_{}'.format(str(i)),
'episode':'story_test_{}'.format(str(i)),
'contents': data,
'label': 1,
'language_code':'KOR'}])
except:
continue
if i == 193447 :
new_data = df.copy()
else:
new_data = pd.concat([new_data, df],axis=0)여기서는 약 3만개의 posts를 크롤링 할 것이다
크롤링 결과를 정리하기위해 pandas dataframe에 해당 정보들을 실었다.
print(new_data.shape)
new_data.head()
'Natural Language Processing' 카테고리의 다른 글
| 텔레그램봇을 활용한 유저 채팅 데이터 수집 및 활용(feat. telepot, telegram) (2) | 2022.03.24 |
|---|---|
| [크롤링] 로그인 후 게시판 목차의 링크를 받아와(n page 까지의 게시물 전체 링크) website 크롤링 (0) | 2020.09.10 |
| [번역 API] Google translate를 이용한 언어 번역 API 사용 (0) | 2020.09.08 |
| Transfer learning 적용 정리 : universal sentence encoder multilingual (0) | 2020.08.10 |
| Transfer Learning (universal-sentence-encoder-multilingual) (0) | 2020.08.10 |


