
250x250
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- chatGPT
- 공분산
- Counterfactual Explanations
- GenericGBQException
- spark udf
- Retry
- API Gateway
- integrated gradient
- youtube data
- subdag
- gather_nd
- GCP
- UDF
- Airflow
- top_k
- XAI
- airflow subdag
- correlation
- tensorflow text
- 상관관계
- login crawling
- 유튜브 API
- grad-cam
- API
- BigQuery
- hadoop
- session 유지
- requests
- TensorFlow
- flask
Archives
- Today
- Total
데이터과학 삼학년
텔레그램 챗 내용 export 및 parser (feat. beautifulsoup) 본문
Natural Language Processing
텔레그램 챗 내용 export 및 parser (feat. beautifulsoup)
Dan-k 2022. 4. 19. 19:56반응형
텔레그램봇을 이용한 텔레그램 챗 수집은 두가지 조건이 있다.
1. 해당 챗방에 봇 초대
2. 봇이 관리자 권한 획득
하지만 위와 같은 상황으로 텔레그램봇을 이용해 데이터를 수집하지 못한다면...
직접 챗방에 들어가 chat data를 export할 수 있다.
[텔레그램챗 수집]
1. 먼저 telegram desktop을 다운받고 설치한다.
2. 원하는 챗방에 들어가서 오른쪽 상단의 설정을 누르면 대화 내보내기(export)가 있다. 해당 버튼을 클릭하면,
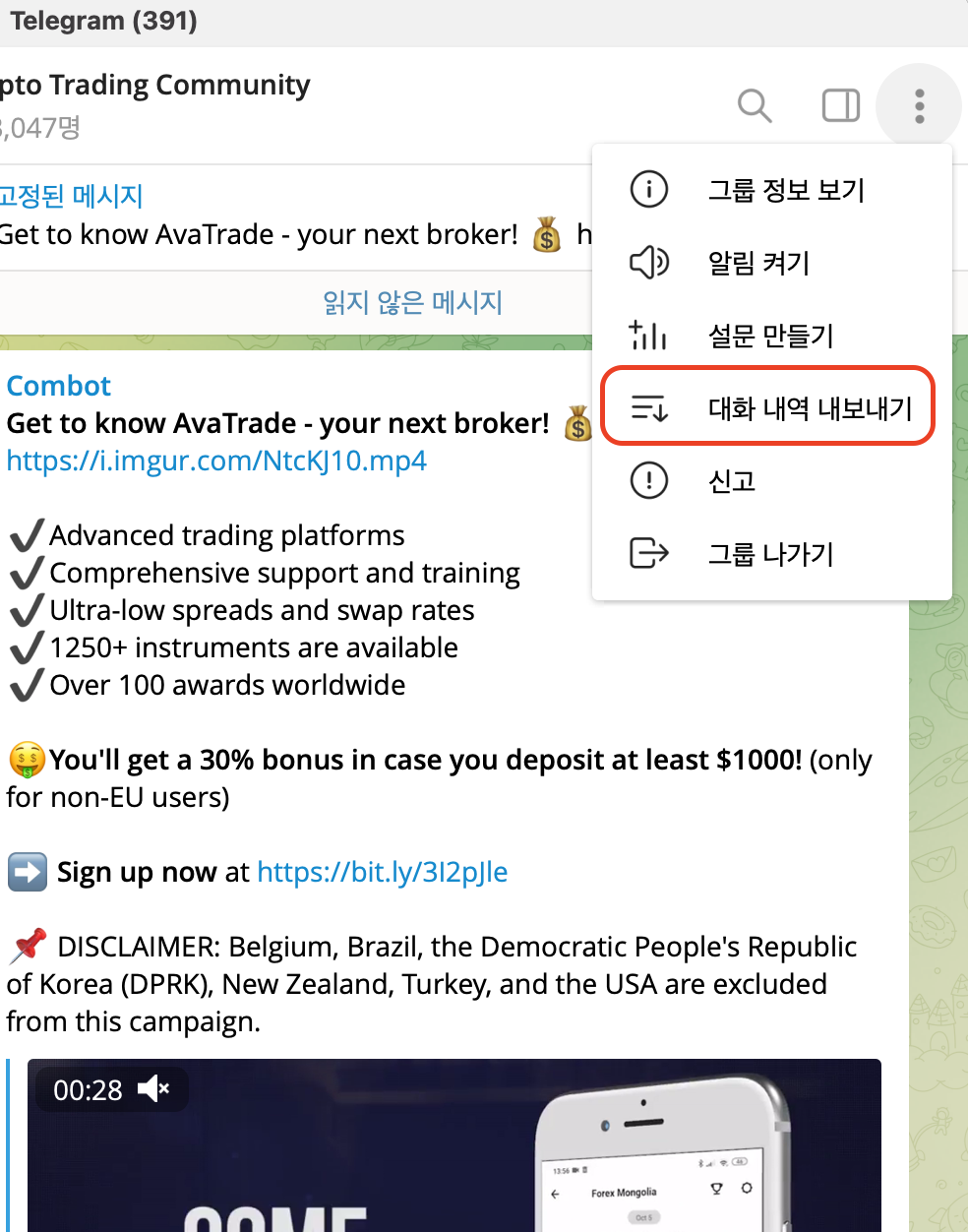
3. 내보내기를 원하는 파일형태와 기간을 설정할 수 있다.
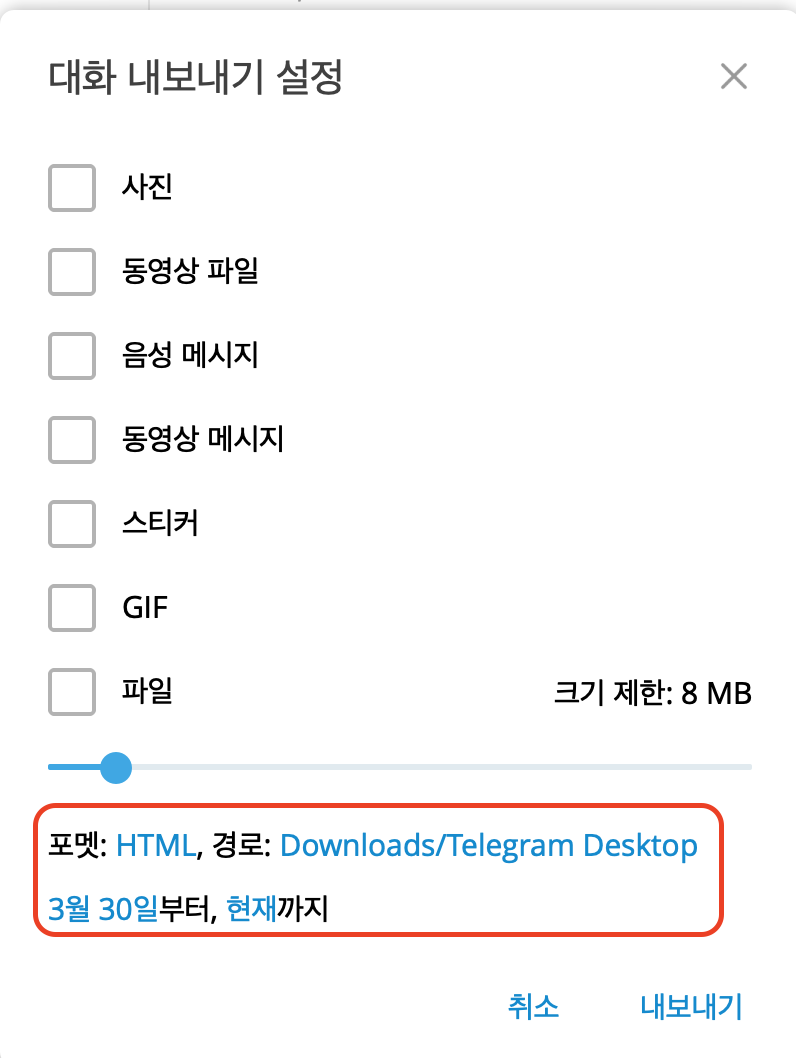
4. 내보내고 나면 챗의 경우는 .html 파일로 받아볼수 있고, html 파서를 이용하여 데이터를 수집하면 된다.

5. html 파일을 파서하여 원하는 데이터를 수집한다.
[html 파일]
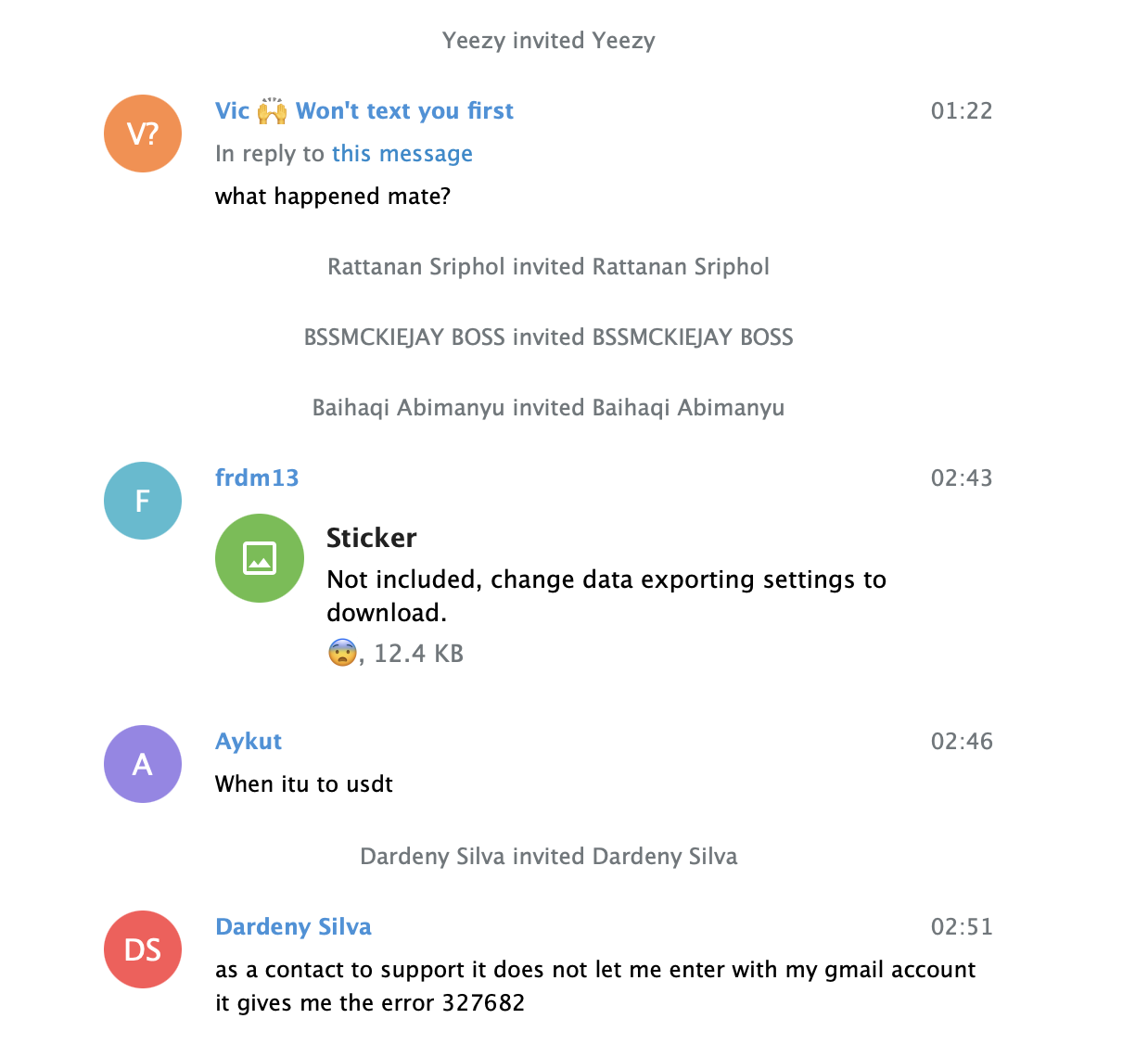
반응형
[html 파서 코드 예시]
from bs4 import BeautifulSoup
import pandas as pd
from pprint import pprint
with open('messages.html') as f:
html = f.read()
def get_date(date_time):
from datetime import datetime
from pytz import timezone
KST = timezone('Asia/Seoul')
temp = datetime.strptime(str(date_time), '%d.%m.%Y %H:%M:%S')
date_time = temp.astimezone(KST).strftime('%Y-%m-%d %H:%M:%S')
date = temp.astimezone(KST).strftime('%Y-%m-%d')
return date, date_time
def get_df(html):
bs = BeautifulSoup(html, 'html.parser')
bodies = bs.find_all('div', attrs={'class': 'body'})
author_name, datetime_lst, message, basis_dt = [], [], [], []
for body in bodies:
bs_temp = BeautifulSoup(str(body), 'html.parser')
texts = bs_temp.find_all('div', attrs={'class': 'text'})
from_names = bs_temp.find_all('div', attrs={'class': 'from_name'})
datetimes = bs_temp.find_all('div', attrs={'class': 'pull_right date details'})
if len(texts) > 0 and len(from_names) == 0:
from_names = [temp_name] * len(texts)
is_from_names = False
else:
is_from_names = True
for datetime, name, text in zip(datetimes,from_names,texts):
if is_from_names :
temp_name = name.get_text().replace('\n','').strip()
date, date_time = get_date(datetime['title'])
author_name.append(temp_name)
datetime_lst.append(date_time)
message.append(text.get_text().replace('\n','').strip())
basis_dt.append(date)
return pd.DataFrame({'author_name':author_name,'datetime':datetime_lst,'message':message,'basis_dt':basis_dt})
df = get_df(html)
df.head(7)
728x90
반응형
LIST
'Natural Language Processing' 카테고리의 다른 글
| ROUGE : text summarization metric (0) | 2022.05.09 |
|---|---|
| TextRank for Text Summarization (0) | 2022.05.04 |
| 텔레그램봇을 활용한 유저 채팅 데이터 수집 및 활용(feat. telepot, telegram) (2) | 2022.03.24 |
| [크롤링] 로그인 후 게시판 목차의 링크를 받아와(n page 까지의 게시물 전체 링크) website 크롤링 (0) | 2020.09.10 |
| [크롤링] 로그인이 필요한 website 크롤링 (2) | 2020.09.09 |
'Natural Language Processing' Related Articles
more




Comments