
- 분류 전체보기 (423)

- Python (37)
- Machine Learning (95)
- Statistical Learning (58)
- Time Series Analysis (13)
- Natural Language Processing (31)
- Data Visualization & DataBa.. (16)
- Recommendation System (11)
- Feature Engineering (11)
- Explainable AI (11)
- GCP (23)
- DevOps (30)
- Web (23)
- Growth Hacking (3)
- Mathematics (3)
- Hadoop (4)
- Frontend (1)
- Computer Science (36)
- Papers (10)
- Etc. (3)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 공분산
- Airflow
- 유튜브 API
- 상관관계
- youtube data
- grad-cam
- session 유지
- spark udf
- tensorflow text
- Counterfactual Explanations
- API Gateway
- Retry
- chatGPT
- BigQuery
- UDF
- correlation
- XAI
- flask
- API
- top_k
- GCP
- GenericGBQException
- TensorFlow
- hadoop
- subdag
- login crawling
- integrated gradient
- gather_nd
- requests
- airflow subdag
- Today
- Total
데이터과학 삼학년
불균형 데이터 오버샘플링 기법: SMOTE, ADASYN, SMOTE-Tomek Link 본문
1. SMOTE (Synthetic Minority Over-sampling Technique)
개념
SMOTE는 소수 클래스(minority class)의 데이터를 합성하여 새로운 데이터를 생성하는 방식의 오버샘플링 기법입니다. 단순히 데이터를 복제하는 것이 아니라, K-최근접 이웃(K-NN) 기반으로 새로운 데이터를 생성하여 데이터의 다양성을 증가시킵니다.
알고리즘
- 소수 클래스의 데이터 샘플을 선택합니다.
- 선택된 샘플의 K-최근접 이웃을 찾습니다.
- 이웃 중 하나를 랜덤하게 선택하여 기존 데이터와의 차이를 계산합니다.
- 이 차이에 랜덤한 값을 곱하고 기존 데이터에 더하여 새로운 데이터를 생성합니다.
장점
- 기존 데이터를 단순 복제하는 것이 아니라, 새로운 데이터를 생성하여 모델의 일반화 성능을 향상시킴.
- 다양한 데이터 분포를 유지하면서 소수 클래스의 샘플 수를 증가시킴.
단점
- 생성된 샘플이 실제 데이터가 아니므로, 원본 데이터의 분포를 왜곡할 가능성이 있음.
- 노이즈가 있는 데이터의 경우, 노이즈까지 증폭될 위험이 있음.

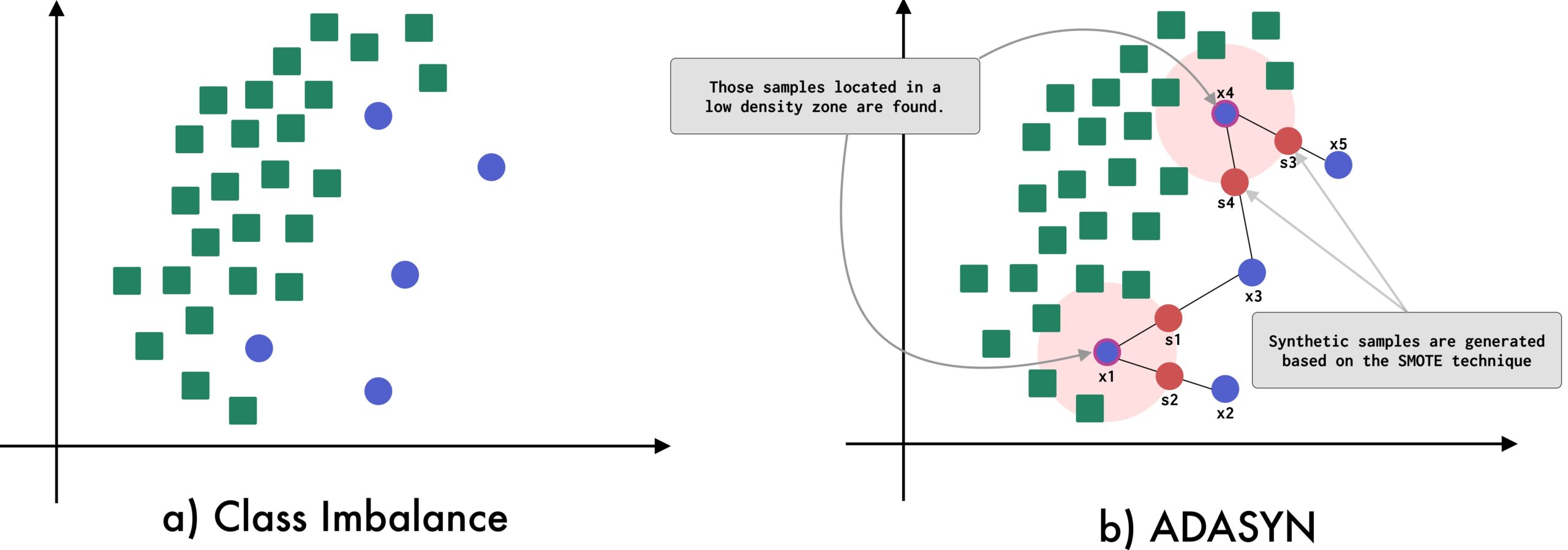
2. ADASYN (Adaptive Synthetic Sampling)
개념
ADASYN은 SMOTE와 유사한 방식으로 새로운 데이터를 생성하지만, 데이터 밀도가 낮은 영역에 더 많은 샘플을 생성하는 방식으로 적응적(adaptive) 오버샘플링을 수행합니다.
알고리즘
- 각 소수 클래스 샘플의 K-최근접 이웃을 찾고, 다수 클래스 샘플과의 비율을 계산하여 샘플링 가중치를 부여합니다.
- 샘플링 가중치가 높은(즉, 데이터 밀도가 낮은) 샘플 주변에서 더 많은 데이터를 생성합니다.
- 새로운 데이터를 생성하는 과정은 SMOTE와 유사하지만, 밀도가 낮은 영역일수록 더 많은 샘플이 추가됩니다.
장점
- 소수 클래스의 데이터 분포를 더욱 자연스럽게 확장할 수 있음.
- 밀도가 낮은 영역을 보완하여 모델의 성능을 향상시킬 가능성이 높음.
단점
- 노이즈가 많은 데이터셋에서는 성능이 저하될 수 있음.
- 계산량이 증가할 가능성이 있음.
3. SMOTE-Tomek Link
개념
Tomek Link는 데이터 정제(cleaning) 기법으로, 클래스 간 경계에 위치한 샘플을 제거하여 더 명확한 분류 경계를 만들도록 돕습니다. SMOTE와 결합하여 오버샘플링과 언더샘플링을 함께 수행하면, 데이터의 균형을 맞추면서도 더 정제된 데이터셋을 만들 수 있습니다.
알고리즘
- SMOTE를 적용하여 소수 클래스 데이터를 합성합니다.
- Tomek Link를 찾아 제거합니다.
- Tomek Link: 두 개의 샘플 (A, B)이 서로의 최근접 이웃이며, A는 다수 클래스, B는 소수 클래스인 경우, B를 제거합니다.
장점
- SMOTE의 단점을 보완하여 경계에 위치한 애매한 샘플을 정리함으로써 모델의 성능 향상 가능.
- 불필요한 데이터 포인트를 줄여 과적합(overfitting) 가능성을 낮춤.
단점
- Tomek Link 제거 과정에서 일부 중요한 경계 데이터까지 손실될 가능성이 있음.
- 데이터 양이 줄어들기 때문에, 성능 향상이 보장되지 않을 수도 있음.
4. 비교
기법 장점 단점
| SMOTE | 데이터 다양성 증가, 과적합 방지 | 데이터 왜곡 가능성, 노이즈 증폭 위험 |
| ADASYN | 밀도가 낮은 영역을 보완, 자연스러운 데이터 생성 | 노이즈가 많은 데이터에서는 성능 저하 가능 |
| SMOTE-Tomek Link | 경계 정리로 모델 성능 향상, 과적합 방지 | 중요한 샘플 손실 가능성, 데이터 감소 |
5. 결론
단순한 오버샘플링이 필요한 경우에는 SMOTE를, 데이터 밀도가 낮은 영역을 보완하고 싶다면 ADASYN을, 데이터 정제까지 함께 고려하고 싶다면 SMOTE-Tomek Link를 고려
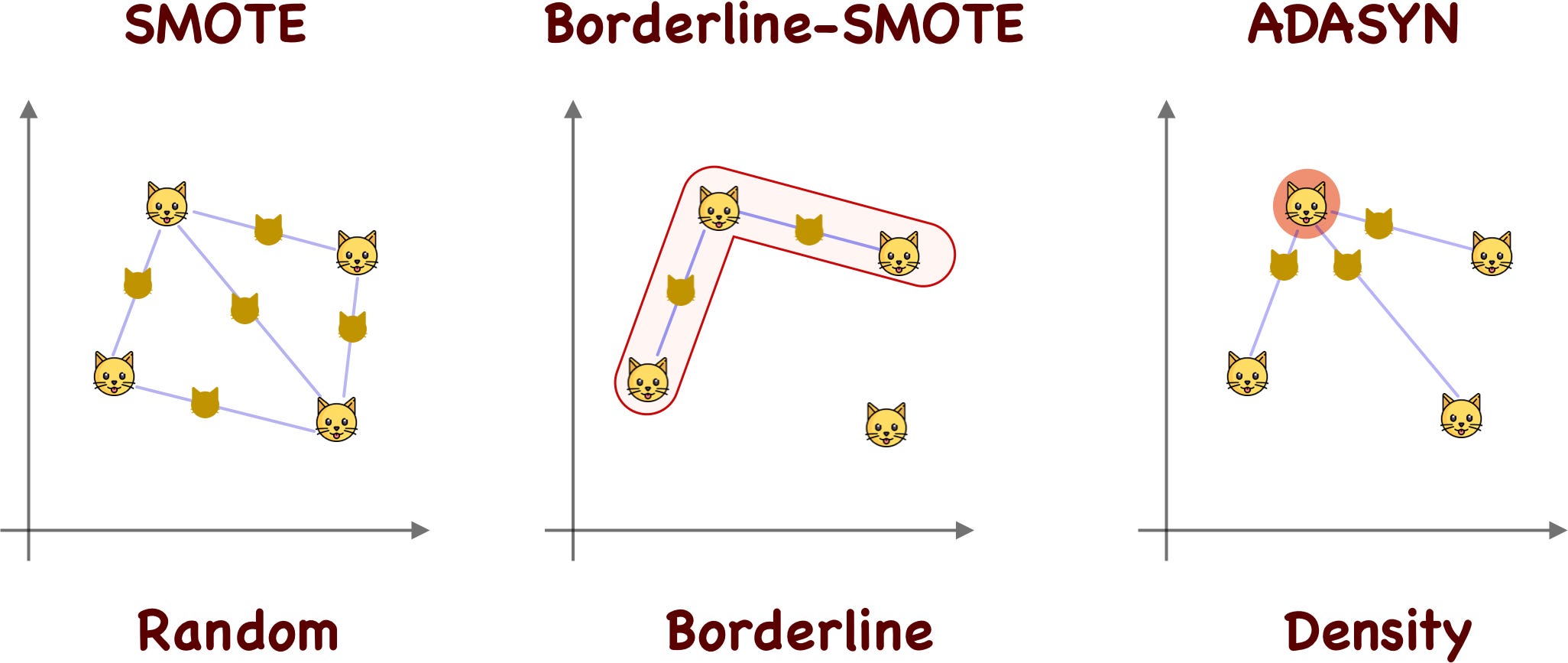
https://towardsdatascience.com/smote-synthetic-data-augmentation-for-tabular-data-1ce28090debc/
SMOTE: Synthetic Data Augmentation for Tabular Data | Towards Data Science
An exploration of SMOTE and some variants like Borderline-SMOTE and ADASYN
towardsdatascience.com
'Statistical Learning' 카테고리의 다른 글
| 큰 수의 법칙, 중심극한의 정리 (0) | 2025.03.16 |
|---|---|
| 네거티브 샘플링 (0) | 2024.12.20 |
| 범주형 변수 상관관계?! -> cross tab with chi square (1) | 2024.11.13 |
| 카파 통계량 (Kappa-statistics) (0) | 2024.02.22 |
| 범주형 변수와 연속형 변수간 상관관계(categorical numerical correlation) (0) | 2023.09.25 |

