
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 유튜브 API
- chatGPT
- spark udf
- airflow subdag
- 상관관계
- TensorFlow
- UDF
- top_k
- tensorflow text
- requests
- API Gateway
- integrated gradient
- grad-cam
- Airflow
- subdag
- Retry
- API
- session 유지
- youtube data
- hadoop
- login crawling
- GenericGBQException
- flask
- XAI
- BigQuery
- 공분산
- correlation
- GCP
- Counterfactual Explanations
- gather_nd
- Today
- Total
데이터과학 삼학년
Kernel Density Estimation (KDE) 본문
Kernel Density Estimation (KDE)을 이용한 이상탐지
- 아래 그림과 같이 기존 데이터가 주어지고, 어떠한 한 Point에 대해 이상치를 탐지한다고 가정
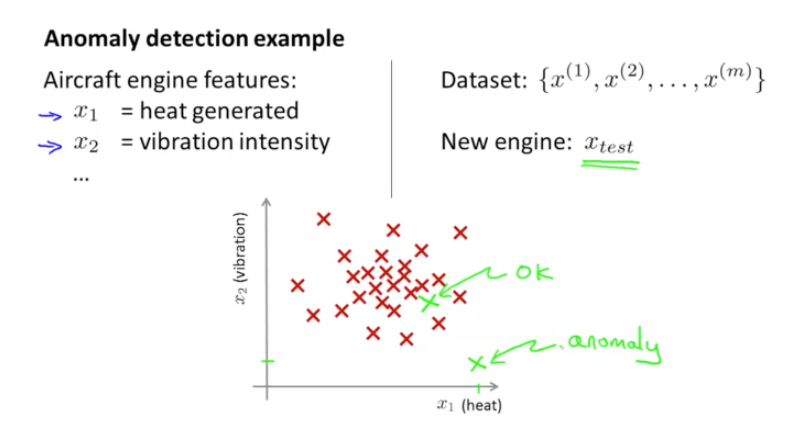
- 위 데이터에 대해 이상치를 구한다고 하면, 초록색으로 표시된 point가 이상치인지는 기존의 data들의 분포를 비교하여 탐지할 수 있음

밀도 기반의 이상탐지 방법
- 두 개의 변수에 대한 분포를 나타냄
- 각 분포의 밀도를 통해 분포에서 벗어난 정도를 이용해 이상치를 탐지
- 데이터의 밀도를 추정하는 함수 P(x)를 이용하여 각 point마다 P(x) 를 산정
- 임계 값인 threshold를 정하고, 해당 point의 함수값이 임계값보다 작은지를 확인하여 이상치 탐지
확률밀도함수를 기반으로 밀도 추정
- parametric
- dataset이 정규분포를 따른다고 가정하고 밀도를 추정하는 방법
- 정규분포는 feature x에 대해 평균에 가까울 수록 밀도가 커지기 때문에 평균과 비슷한 데이터가 제일 많을 것이라고 가정하고 밀도 추정
- non-parametric
- 순수하게 관측된 데이터 만으로 확률밀도함수를 만들어야 함
- 실제 데이터는 정규분포를 따르지 않는 경우가 많음
- 순수하게 관측된 데이터 만으로 확률밀도함수를 만들어야 함
kernel을 이용한 밀도 추정 (Kernel Density Estimation)
- kernel 의 종류

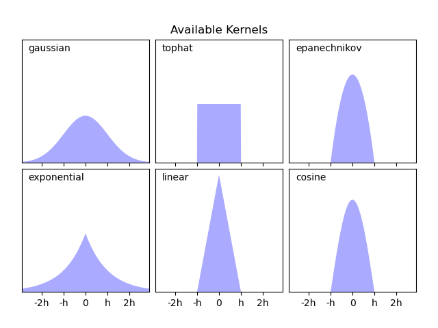
- kernel의 조건
1. 전 구간에서 함수값이 양수여야함
K(x) >= 02. 대칭적이어야함K(x) = K(-x)3. 함수의 중아에서 멀어질수록 함수값이 감소해야함K'(x) <= 0 (x >0)
Gaussian kernel을 이용한 Kernel Density Estimation
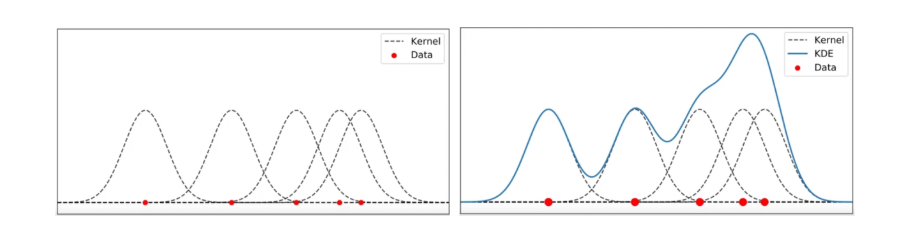
1. 데이터를 뿌린다

2. 각 데이터가 중심인 가우시안 분포를 그린다
3. 그려진 분포를 모두 더하여 새로운 분포를 생성
>> 위 모든 과정은 공식으로 한번에 추정할 수 있음
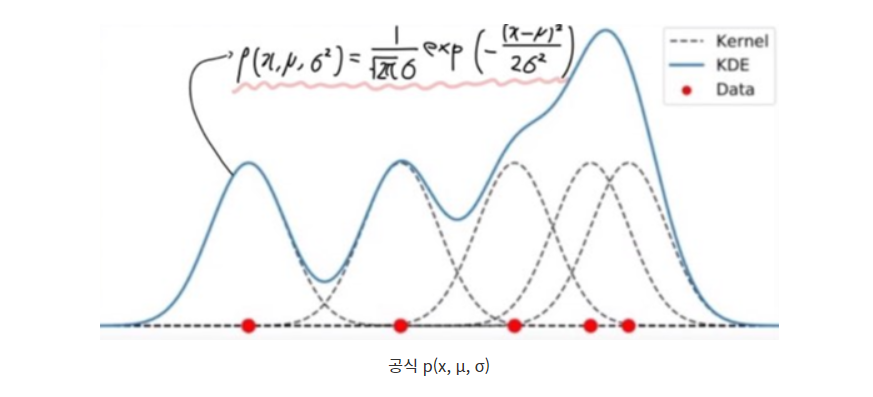
* bandwidth를 조정하여 분포를 smoothing 시킴

KDE를 이용한 이상치 탐지
1. 데이터 임의 생성
|
data = [ [10, 22, 31], [10, 11, 229], [11, 22, 33], [1121, 52, 34], [33333, 11, 23111], [121, 232, 323], [11221, 5112, 234], [1331, 2232, 313], [11221, 5222, 3411], [123123123, 111, 2111113], [123123123, 111, 2111115], [1331, 2232, 313] ] |
2. 각 데이터는 KDE를 통해 score를 구할수 있음
- score = log(probability) → 음수의 절대값이 클수록 작은 확률을 의미 → 이상치로 판단
- score는 각 data가 정상 밀도 범위 안에 있다고 판단되는 probability를 의미함
3.Kernel Density score를 각 데이터마다 산정
|
[-3.28560071 -3.28678686 -3.2856007 -3.2824958 -3.2870753 -3.26791354 -4.20440431 -3.49171431 -4.23326744 -4.5459095 -4.54590952 -3.49171431] |
- Threshold 설정
> 관찰된 kernel density를 통한 확률 값이 일정 quantile 보다 작은지 확인
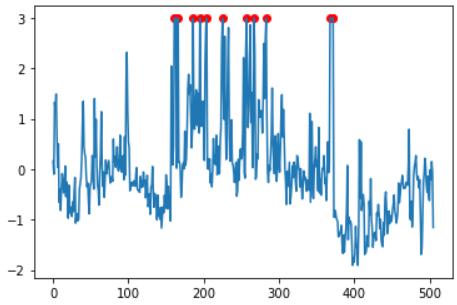
탐지방법 요약
1. 모든 feature에 대해 각 feature의 데이터들이 중심으로 된 kernel 을 생성하고, 분포를 모두 더해 각 feature에 대한 확률 밀도 함수 KDE를 생성함
2. 각 Feature의 KDE를 곱하여 정상일 확률인 P(x)를 구함
3. 전체 데이터 셋의 Quantile 이나 이상치 데이터의 P(x) 값을 확인해 임계값을 설정하고, 해당 임계값보다 작은 point를 이상치라 판단함
참조
https://scikit-learn.org/stable/modules/density.html
https://www.datatechnotes.com/2020/05/anomaly-detection-with-kernel-density-in-python.html
https://box-world.tistory.com/35
'Statistical Learning' 카테고리의 다른 글
| interpolation(보간법, 내삽) VS extrapolation(보외법, 외삽) (0) | 2022.01.17 |
|---|---|
| KS test (Kolmogorov–Smirnov test) (0) | 2021.05.25 |
| 요인분석 (Factor Analysis, Latent variable) (0) | 2021.04.15 |
| 샘플링 (Sampling) (0) | 2021.04.05 |
| Edit Distance (Levenshtein Distance) (퍼옴) (1) | 2021.04.01 |


