
250x250
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
Tags
- chatGPT
- Counterfactual Explanations
- API Gateway
- tensorflow text
- integrated gradient
- BigQuery
- grad-cam
- flask
- top_k
- correlation
- 상관관계
- spark udf
- GCP
- 유튜브 API
- hadoop
- UDF
- subdag
- Retry
- session 유지
- 공분산
- Airflow
- XAI
- airflow subdag
- gather_nd
- TensorFlow
- API
- youtube data
- GenericGBQException
- requests
- login crawling
Archives
- Today
- Total
데이터과학 삼학년
interpolation(보간법, 내삽) VS extrapolation(보외법, 외삽) 본문
반응형
데이터에 결측치가 많다면 다른 데이터를 이용하여 결측치를 추정할 수 있다.
정확하지 않지만 결측치를 추정하는 방법에는 주어진 데이터 범위 내의 값을 추정하냐, 범위 밖에 값을 추정하냐로, interpolation, extrapolation으로 구분할 수 있다.
interpolation(보간법, 내삽)
- 범위 안에 있는 값을 예측하는 것
- interpoltaion의 방법에 따라 선형, 스플라인,

extrapolation(보외법, 외삽)
- 범위 밖에 있는 값을 예측하는 것
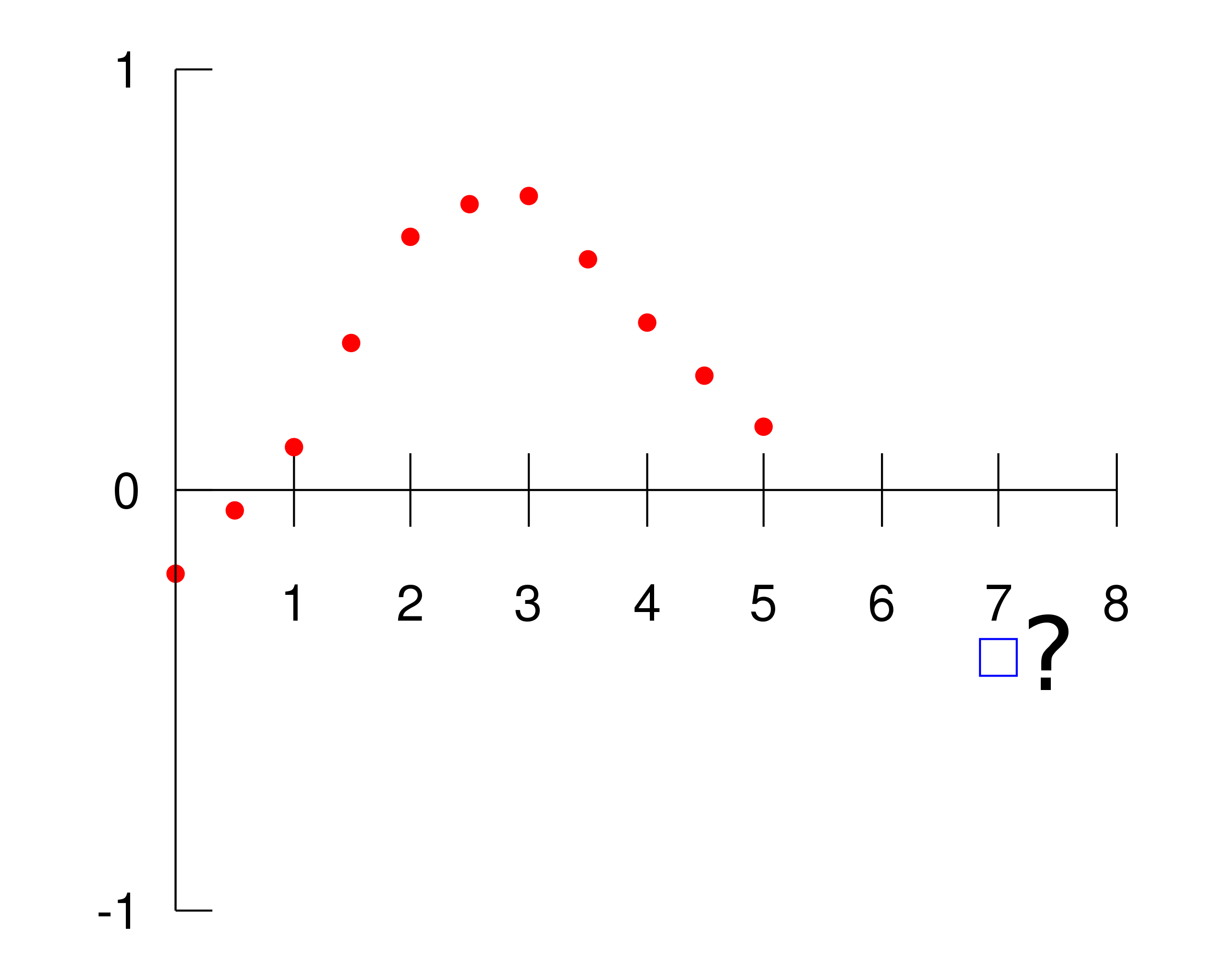
interpolation(보간법, 내삽) VS extrapolation(보외법, 외삽)

s = pd.Series([0, 1, np.nan, 3])
s
0 0.0
1 1.0
2 NaN
3 3.0
dtype: float64
s.interpolate()
0 0.0
1 1.0
2 2.0
3 3.0
dtype: float64
s = pd.Series([np.nan, "single_one", np.nan,
"fill_two_more", np.nan, np.nan, np.nan,
4.71, np.nan])
s
0 NaN
1 single_one
2 NaN
3 fill_two_more
4 NaN
5 NaN
6 NaN
7 4.71
8 NaN
dtype: object
s.interpolate(method='pad', limit=2)
0 NaN
1 single_one
2 single_one
3 fill_two_more
4 fill_two_more
5 fill_two_more
6 NaN
7 4.71
8 4.71
dtype: object
s = pd.Series([0, 2, np.nan, 8])
s.interpolate(method='polynomial', order=2)
0 0.000000
1 2.000000
2 4.666667
3 8.000000
dtype: float64
df = pd.DataFrame([(0.0, np.nan, -1.0, 1.0),
(np.nan, 2.0, np.nan, np.nan),
(2.0, 3.0, np.nan, 9.0),
(np.nan, 4.0, -4.0, 16.0)],
columns=list('abcd'))
df
a b c d
0 0.0 NaN -1.0 1.0
1 NaN 2.0 NaN NaN
2 2.0 3.0 NaN 9.0
3 NaN 4.0 -4.0 16.0
df.interpolate(method='linear', limit_direction='forward', axis=0)
a b c d
0 0.0 NaN -1.0 1.0
1 1.0 2.0 -2.0 5.0
2 2.0 3.0 -3.0 9.0
3 2.0 4.0 -4.0 16.0
df['d'].interpolate(method='polynomial', order=2)
0 1.0
1 4.0
2 9.0
3 16.0
Name: d, dtype: float64https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.interpolate.html
728x90
반응형
LIST
'Statistical Learning' 카테고리의 다른 글
| 선형 회귀 분석의 가정 (1) | 2022.05.23 |
|---|---|
| Needleman-Wunsch algorithm(니들만-브니쉬(분쉬) 알고리즘) (0) | 2022.01.24 |
| KS test (Kolmogorov–Smirnov test) (0) | 2021.05.25 |
| Kernel Density Estimation (KDE) (0) | 2021.05.03 |
| 요인분석 (Factor Analysis, Latent variable) (0) | 2021.04.15 |
'Statistical Learning' Related Articles
more




Comments