
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- chatGPT
- API
- flask
- Retry
- 공분산
- TensorFlow
- requests
- integrated gradient
- GCP
- youtube data
- 상관관계
- session 유지
- BigQuery
- airflow subdag
- subdag
- UDF
- login crawling
- GenericGBQException
- correlation
- XAI
- 유튜브 API
- API Gateway
- Airflow
- Counterfactual Explanations
- grad-cam
- tensorflow text
- gather_nd
- hadoop
- spark udf
- top_k
- Today
- Total
데이터과학 삼학년
샘플링 (Sampling) 본문
샘플링이란, 모집단의 데이터에서 최대한 모집단과 유사한 일부 데이터를 추출하는 과정이다.
데이터 샘플링 방법은 크게 확률적 샘플링, 비확률적 샘플링으로 구분할 수 있다.
확률적 샘플링 : 무작위 샘플링
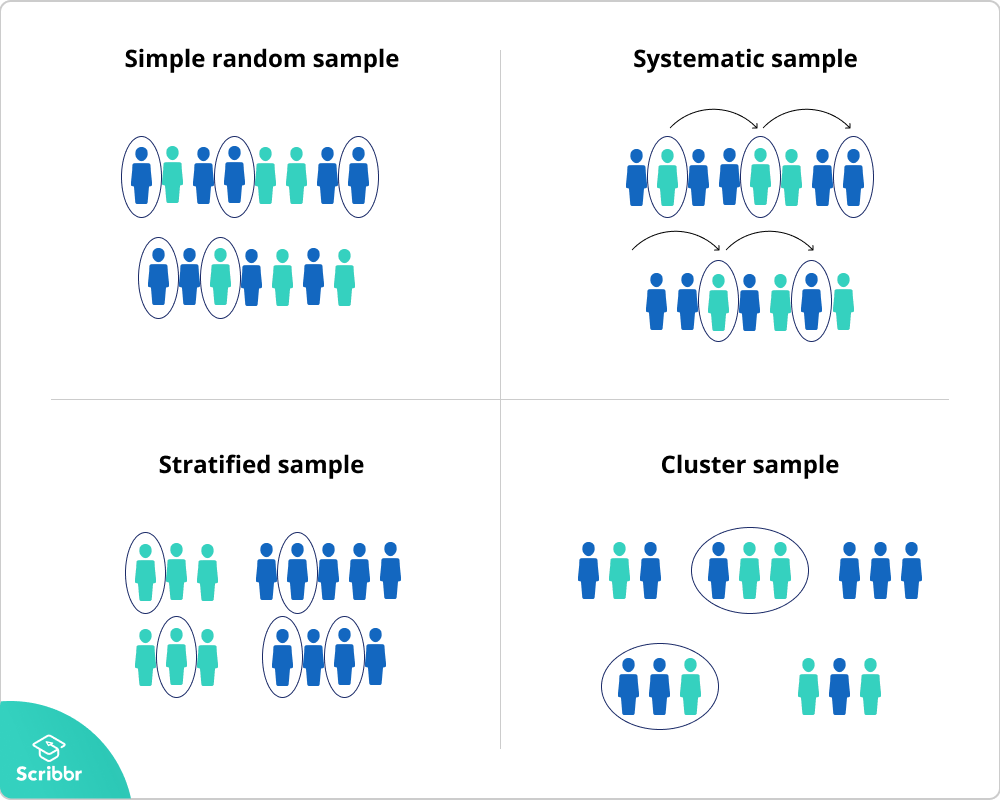
1. 단순 샘플링 (Simple Random Sampling)
- 모집단에서 단순 무작위로 샘플을 추출하는 방법 (각 데이터가 뽑힐 확률이 동일)
2. 층화 샘플링 (Stratified Random Sampling)
- 모집단을 몇 개의 그룹으로 나누어 각 그룹에서 무작위로 n개씩 추출하는 방법
ex) 행정구역으로 나눠 각 행정구역에서 표본 추출
3. 계통 샘플링 (Systematic Sampling)
- 모집단에 있는 데이터들에게 1~n개의 번호를 임의로 매긴 다음, 일정 간격마다 데이터를 추출하는 방법
ex) 시계열 데이터의 대표값을 샘플링하는데 주로 이용
4. 집락/군집 샘플링 (Cluster Sampling)
- 모집단을 여러개의 Cluster로 부분 집단으로 분할하고, 군집 중 하나 or 여러개의 군집을 선정해서
선정된 군집의 전체 데이터를 사용
ex) 행정구역 몇개를 선정해 해당 데이터를 모두 사용
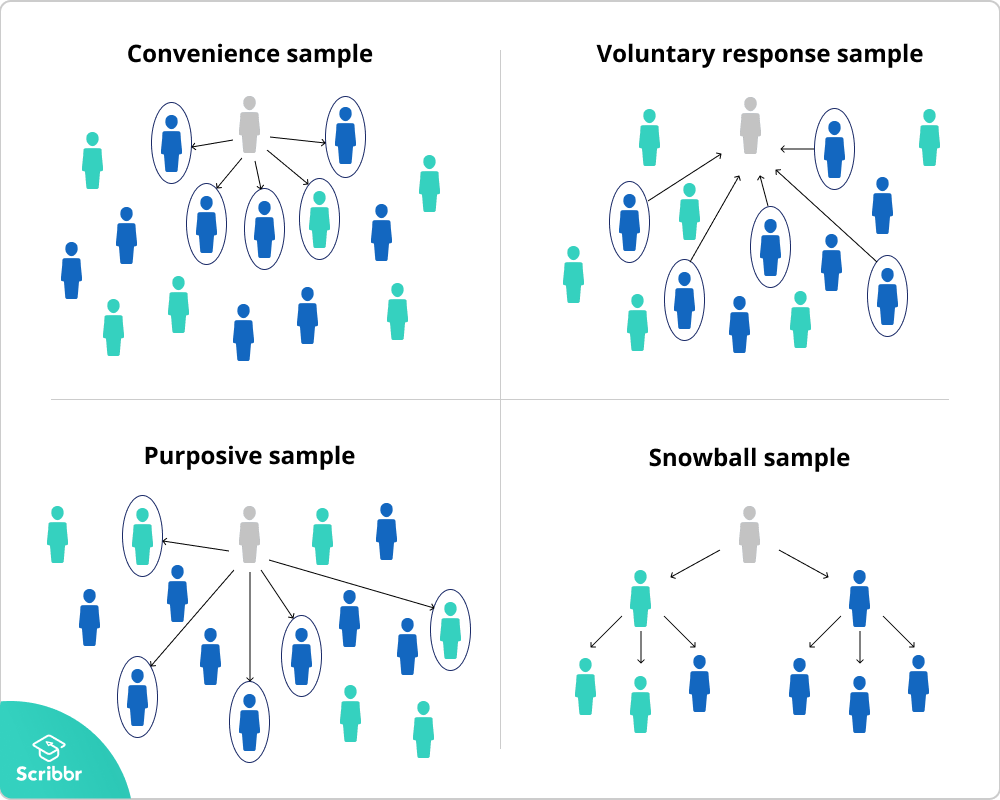
비확률적 샘플링 : 사전에 표본 선정 확률을 모르는 상태로 추출 -> 사람의 주관적인 의도가 개입
1. 편의 샘플링 (Convenience Sampling)
- 데이터를 수집하기 좋은 시점이나 위치를 선정하여 샘플링 (통계적 추론 할 수 없음)
2. 판단 샘플링 (Purpose Sampling)
- 목적에 가장 적합한 대상이라고 생각하는 대상을 선택
- 주관적인 목적에 적합한 데이터를 샘플링 --> 모집단에 대한 대표성이 떨어짐
3. 할당 샘플링 (Quota Sampling)
- 모집단을 세그먼트로 구분하여 각 세그먼트에 표본 수를 나타내는 쿼타를 할당
- 세그먼트는 주제와 관련된 특성이 비슷해야하며 세그먼트 간 거의 다르게 모집단을 나눔 (층별 샘플링과 유사)
www.scribbr.com/methodology/sampling-methods/
Sampling Methods | Types and Techniques Explained
To draw valid conclusions, you must carefully choose a sampling method. Sampling allows you to make inferences about a larger population.
www.scribbr.com
ML #5 : 머신러닝 데이터 샘플링 방법과 필요성 (확률적, 비확률적 샘플링)
데이터 샘플링 필요성 머신러닝에서 입력 데이터가 많아지면 처리 속도가 느려지게 됩니다. 그렇기 때문에 머신러닝의 처리 속도를 빠르게 하기 위해서 대표되는 데이터로 최적화한 후에 머신
muzukphysics.tistory.com
[통계] 샘플링(Sampling)
* 샘플링 방법과 Bias에 대한 자세한 내용은 아래의 Ref. 부분을 참고 부탁드립니다. 샘플링은 모집단에서 일정한 수만큼 추출하는 작업을 말한다. 샘플링은 개별 관측치의 선택과 관련된 통계적
rucrazia.tistory.com
'Statistical Learning' 카테고리의 다른 글
| Kernel Density Estimation (KDE) (0) | 2021.05.03 |
|---|---|
| 요인분석 (Factor Analysis, Latent variable) (0) | 2021.04.15 |
| Edit Distance (Levenshtein Distance) (퍼옴) (1) | 2021.04.01 |
| Mahalanobis Distance (0) | 2021.04.01 |
| 생존 분석 (Survival Analysis) - 퍼옴 (0) | 2021.04.01 |


