
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 유튜브 API
- top_k
- requests
- XAI
- 공분산
- correlation
- login crawling
- gather_nd
- youtube data
- grad-cam
- airflow subdag
- Counterfactual Explanations
- 상관관계
- GCP
- UDF
- Retry
- integrated gradient
- chatGPT
- session 유지
- API Gateway
- Airflow
- flask
- GenericGBQException
- BigQuery
- hadoop
- API
- spark udf
- tensorflow text
- TensorFlow
- subdag
- Today
- Total
데이터과학 삼학년
Edit Distance (Levenshtein Distance) (퍼옴) 본문
Levenshtein Distance
- 두 개의 문자열 A, B가 주어졌을 때 두 문자열이 얼마나 유사한 지를 알아낼 수 있는 알고리즘
- 문자열 A가 문자열 B와 같아지기 위해서는 몇 번의 연산을 진행해야 하는 지 계산할 수 있음
> 연산이란, 삽입(Insertion), 삭제(Deletion), 대체(Replacement)를 말합니다.
예시
1. 문자열 A가 ‘대표자’ 라는 뜻을 가진 ‘delegate’ 라고 가정하고 문자열 B는 ‘삭제’ 라는 뜻을 가진 ‘delete’ 라고 가정합니다.
- 문자열 A에서 5번 째 문자 g와 6번 째의 문자 a가 삭제되면 문자열 B가 동일해집니다. 즉, 여기서의 연산 횟수는 2가 되는 것이지요.
2. 문자열 A가 ‘과정’ 을 뜻하는 ‘process’ 라고 가정하고 문자열 B가 ‘교수’ 를 뜻하는 ‘professor’ 라고 가정해봅시다.
- 먼저, 문자열 A에서 4번 째에 위치한 문자 c를 문자 f로 대체합니다. 그 결과는 profess가 됩니다. 그 다음으로 마지막에 위치에 문자 o를 삽입합니다. 이 때의 결과는 professo가 됩니다. 마지막으로 또 다시 가장 마지막 위치에 문자 r을 삽입합니다. 최종적으로 문자열 B와 동일한 ‘professor’가 완성됩니다.
- 여기서는 1번의 대체 연산과 2번의 삽입 연산을 진행했으므로 총 연산 횟수는 3이 됩니다.
의사 코드(Pseudo code)
의사 코드로 리벤슈테인 거리(또는 편집거리)를 살펴봅시다.
int LevenshteinDistance(char s[1..m], char t[1..m])
{
declare int d[0..m, 0..n]
clear all emenets in d // set each element to zero
for i from 1 to m
d[i, 0] := i
for j from 1 to n
d[0, j] := j
for j from 1 to n
{
for i from 1 to m
{
if s[i] = t[j] then d[i, j] := d[i-1, j-1]
else d[i, j] := minimum(d[i-1, j]+1, d[i, j-1]+1, d[i-1, j-1]+1)
}
}
return d[m, n]
}주의깊게 살펴야 하는 부분은 17번 라인의 코드입니다. 동일한 인덱스에서 문자열 A와 B를 탐색했을 때 값이 서로 같지 않은 경우에 연산 횟수가 더해지는 부분입니다. 아래와 같이 매트릭스(행렬)로 진행 과정을 살펴볼 수 있습니다.
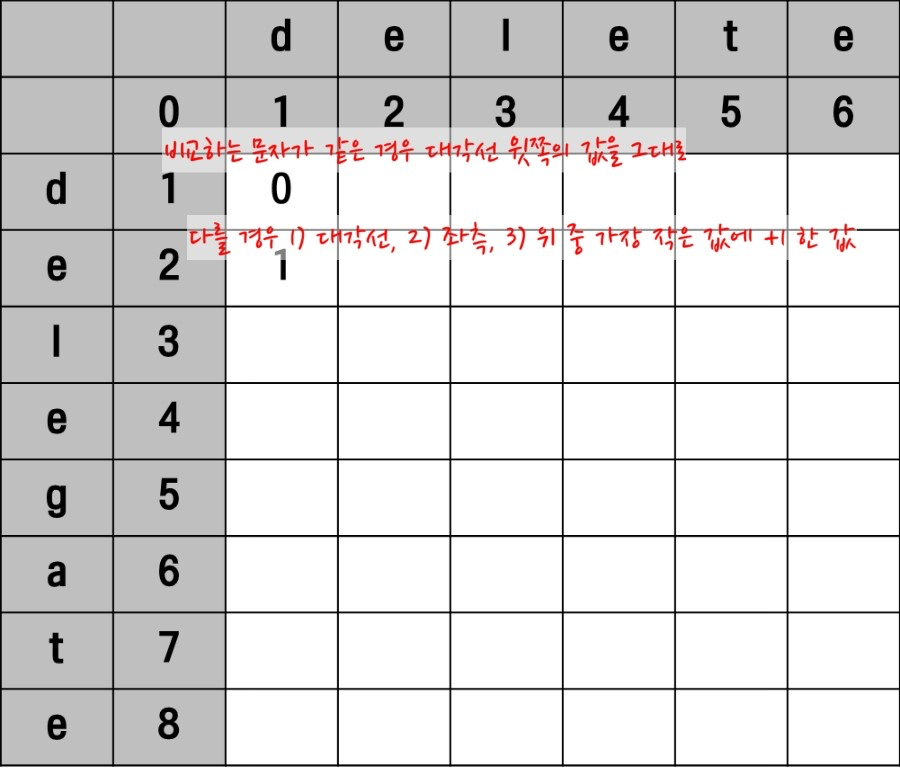
문자열 A의 delegate와 문자열 B의 delete의 첫 번째 문자는 둘 다 ‘d’이므로 같습니다. 따라서 위의 의사 코드(pseudo code)로 표현한 알고리즘의 16번 라인의 코드처럼 대각선으로 위에 있는 값을 그대로 갖습니다.
다음으로 비교되는 문자열 A의 두 번째 문자 e와 문자열 B의 첫 번째 d는 서로 다른 문자입니다. 이러한 경우는 17번 라인의 코드처럼 대각선 위, 좌측, 바로 위 중 가장 작은 값에 1을 더한 값을 갖습니다.
이러한 과정을 계속 진행해보면 아래와 같이 최종적인 매트릭스의 모습을 확인할 수 있습니다.

우측 가장 하단에 있는 숫자 2가 뜻하는 것은 문자열(delegate) A가 문자열(delete) B와 서로 같아지기 위한 연산의 횟수가 됩니다.
파이썬 코드
import editdistance
editdistance.eval('banana', 'bahama')
===
2Limport Levenshtein
import numpy as np
import random
import string
## Algorithm -------------------------------------------------------------------
def edit_distance(s, t):
"""Edit distance of strings s and t. O(len(s) * len(t)). Prime example of a
dynamic programming algorithm. To compute, we divide the problem into
overlapping subproblems of the edit distance between prefixes of s and t,
and compute a matrix of edit distances based on the cost of insertions,
deletions, matches and mismatches.
"""
prefix_matrix = np.zeros((len(s) + 1, len(t) + 1))
prefix_matrix[:, 0] = list(range(len(s) + 1))
prefix_matrix[0, :] = list(range(len(t) + 1))
for i in range(1, len(s) + 1):
for j in range(1, len(t) + 1):
insertion = prefix_matrix[i, j - 1] + 1
deletion = prefix_matrix[i - 1, j] + 1
match = prefix_matrix[i - 1, j - 1]
if s[i - 1] != t[j - 1]:
match += 1 # -- mismatch
prefix_matrix[i, j] = min(insertion, deletion, match)
return int(prefix_matrix[i, j])
## Ensure that the algorithm was correctly implemented --------------------------
def id_generator(size, chars=string.ascii_uppercase + string.digits):
"""Randomly generate an 'id' of characters and digits, taken from
StackOverFlow question #2257441.
"""
return ''.join(random.choice(chars) for _ in range(size))
def generate_random_string(min=1, max=20):
"""Generate a random 'id' string of a random length
"""
size = random.randint(min, max)
return id_generator(size)
# Generate random strings
random.seed(100)
random_strings1 = [generate_random_string() for _ in range(1000)]
random_strings2 = [generate_random_string() for _ in range(1000)]
# Compute edit distances using my function, and Levenshtein.distance
edit_distances_jake = [edit_distance(a, b) for a, b in
zip(random_strings1, random_strings2)]
edit_distances_lev = [Levenshtein.distance(a, b) for a, b in
zip(random_strings1, random_strings2)]
# Are the edit distances the same?
edit_distances_jake == edit_distances_lev
madplay.github.io/post/levenshtein-distance-edit-distance
편집거리 알고리즘 Levenshtein Distance(Edit Distance Algorithm)
문자열 간의 유사도를 알아내는 편집거리 알고리즘을 살펴보자.
madplay.github.io
gist.github.com/jakesherman/93a3c8fa96cf5d2b34df608d1c9b4bc7
'Statistical Learning' 카테고리의 다른 글
| 요인분석 (Factor Analysis, Latent variable) (0) | 2021.04.15 |
|---|---|
| 샘플링 (Sampling) (0) | 2021.04.05 |
| Mahalanobis Distance (0) | 2021.04.01 |
| 생존 분석 (Survival Analysis) - 퍼옴 (0) | 2021.04.01 |
| Maximum Likelihood Estimation (Simple Error Bound) (1) | 2021.03.17 |


