
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- login crawling
- GenericGBQException
- subdag
- integrated gradient
- UDF
- flask
- chatGPT
- 유튜브 API
- session 유지
- correlation
- requests
- GCP
- TensorFlow
- XAI
- Retry
- API Gateway
- youtube data
- gather_nd
- top_k
- BigQuery
- 상관관계
- API
- grad-cam
- 공분산
- spark udf
- Counterfactual Explanations
- airflow subdag
- hadoop
- Airflow
- tensorflow text
- Today
- Total
데이터과학 삼학년
구조방정식(structural equation modeling, SEM) 본문
여러개의 독립변수와 여러개의 종속변수를 분석할 수 있다.
다중 독립변수, 다중 종속변수 분석에 용이함
1. 개념
구조방정식 모델링(構造方程式 - , 영어: structural equation modeling, SEM)은 경로 분석, 회귀 분석, 요인 분석이 합성되어 발전된 통계 방법이다. 구조방정식 모델링의 특징은 직접 측정할 수 없는 잠재변수(Latent variable)를 분석에 포함시킬 수 있다는 것이다. 따라서 사회과학 분야에서 각광받아온 방법론이나, 최근에는 자연과학 분야에서도 응용하려는 움직임이 나타나고 있다.
구조 방정식 모형에서 인과관계 모형을 밝혀내기 위해서는 측정이 타당하고 신뢰할 수 있어야 하며 충분한 사례 수가 필요하다. 변인이 많아지면 분석에 요구되는 사례수가 늘어나며, 인과 모형의 복잡도에 의해서도 필요한 사례수가 변화한다.(wiki)

2. 분석 종류
경로분석(Path analysis), 확인적 요인분석(Confirmatory Factor Analysis: CFA), 잠재성장곡선모형(Latent Growth Curve Modeling), 구조회귀모형(Structural Regression Modeling), 조절분석(Moderation analysis), 매개분석(Mediation analysis)등을 구조방정식 모형을 통해 할 수 있다.

3. 구조방정식 기본 개념
측정모형(확인적 요인분석) + 구조모형(경로분석)

4. 구조 방정식의 변수
• 측정변수(observed variables, indicators): 측정된 변수
• 잠재변수(latent variables, constructs): 측정변수로 만들어낸 새로운 변수
- 외생 잠재변수(exogenous): 원인이 되는 잠재변수
- 내생 잠재변수(endogenous): 결과가 되는 잠재변수
• 오차변수(error variables): 측정오차, 구조오차 측정오차는 구조방정식에만 있으며, 일반선형회귀분석이나 경로 분석은 구조오차만 인정함


5. 구조 방정식의 장단점
- 구조방정식의 장점
• 많은 수의 요인들이 영향을 미치는 효과를 분석 – 다중공선성 문제 해결
• 잠재변수의 활용 – 유사한 요인들의 결합효과 분석, 측정오차의 인정과 산출
• 직간접 인과관계 분석 – 현상에 대한 구조적 분석
- 구조방정식의 단점
• 엄격한 분포 가정(다변량 정규분포)
• 결과의 신뢰성 확보를 위해 표본수가 커야함(추정모수의 5-10배, 최소 150개 이상)
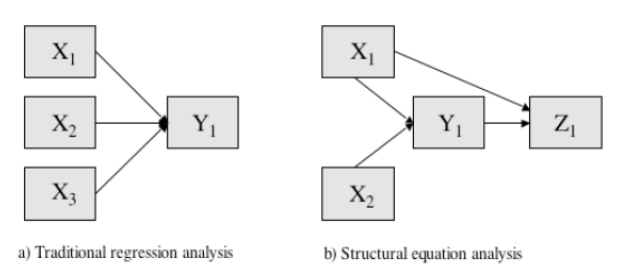
6. 구조 방정식 모형 설정
- 측정모형은 측정변수를 이용해 잠재변수를 생산
• 잠재변수는 구성개념 (Construct) 이 직접 관찰되거나 측정이 되지 않는 변수
• 관측변수 (observed variable)로 간접 측정
- 확인적 요인분석
• 이론적인 배경을 바탕으로 잠재변수를 구성
• 항목들이 이미 정해진 상태로 모델이 만들어지고 그 상황 하에서 분석
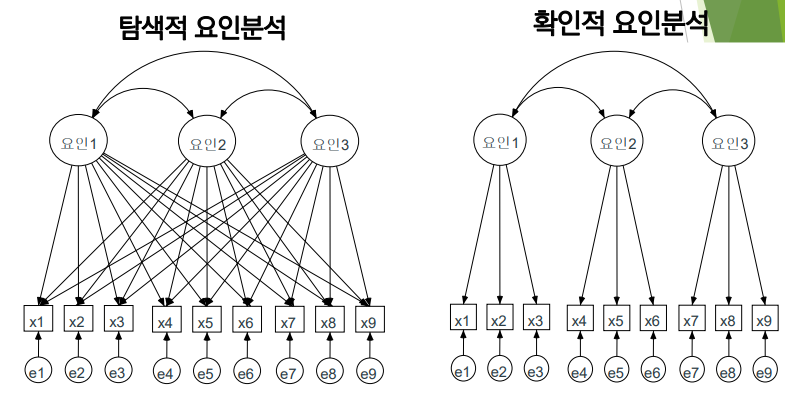
• 측정 오차 (Measurement error) : 잠재변수를 완전하게 설명하지 못하는 정도를 나타낸다.
> 측정 오차: 우리가 사용하는 대부분의 자료는 측정오차를 가지고 있음
> 측정오차의 고려는 구조방정식에서 잠재변수를 사용하는 큰 이유 중 하나임
• 구조적 오차 (Structural error) : 구조적 오차는 내생 변수가 하나 혹은 그 이상의 외생변수에 의해서 설명이 되지 않은 변량을 의미한다.
7. 구조 방정식 모형 평가 지표
- 카이제곱 검정 : 설정된 모형의 정보와 데이터 간 일치 여부 판정 : 제약 모형과 비제약 모형 간 차이 비교
- 수렴타당성(convergent) : 잠재변수와 측정변수 간 관계(AVE > 0.5, CP > 0.7)

- 판별적타당성(discriminant) : 잠재변수 간 차별성 : 다른 잠재변수와 상관관계(상관계수 제곱)보다 분산추출지수가 높아야 함
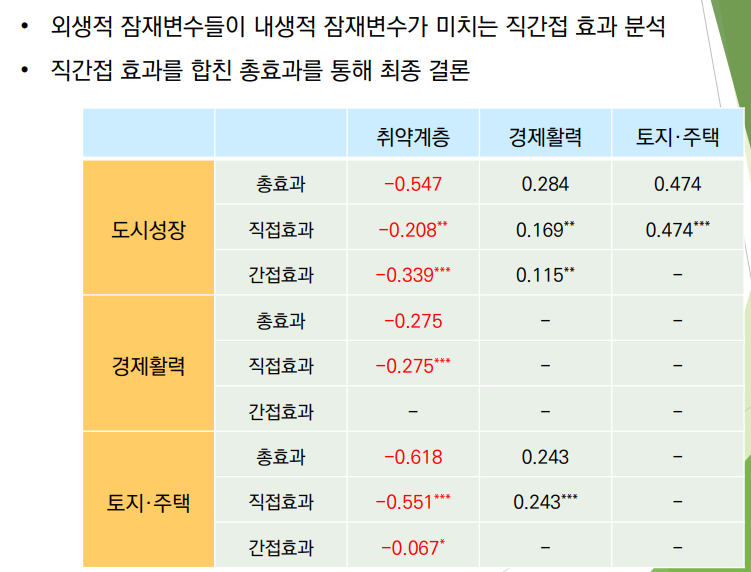
8. 구조 모델 효과
• 직접효과(direct): 외생잠재변수와 내생 잠재변수 간 직접적 인과관계
• 간접효과(indirect), 매개효과(mediated) : 다른 잠재변수를 통한 인과 효과 잠재변수 간 직접효과만 있는 모형은 인자분석으로 산출한 인자를 이용한 다중선형 회귀분석과 같다.

• 총효과(total): 직접효과 + 간접효과
• 조절효과(moderating): 직접 효과를 조절하는 효과

9. 구조 모델 평가 및 수정
• 모형의 전체 평가는 적합 지수들을 이용해 평가
• 측정모형은 타당도와 신뢰도를 함께 평가
- 수렴타당성: 잠재변수가 얼마나 측정지표를 잘 반영하고 있는가
- 판별타당성: 잠재변수들의 의미가 얼마나 판별력이 있는가
• 단 조형지표를 이용한 모형에서는 타당도와 신뢰도를 판별하지 않음


10. 구조 방정식 결과 해석
• 종속변수에 영향을 주는 요인(잠재변수) 선정
• 잠재변수를 나타낼 수 있는 측정지표 선정
• 측정지표와 잠재변수 간 가중치를 통해 잠재변수의 의미 정의


하...구조방정식...좀 어렵다......
춸처 : 브라운백세미나_구조방정식_게시
'Statistical Learning' 카테고리의 다른 글
| [기초통계] t-statistic, p-value, F-statistic (1) | 2020.02.10 |
|---|---|
| [기초통계] 잔차와 오차 (0) | 2020.02.05 |
| [기초통계] 통계적 분석방법 (0) | 2020.02.04 |
| [기초통계] R-square (0) | 2020.02.04 |
| [ISLR] Statistical Learning (0) | 2020.02.03 |



