
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- XAI
- 유튜브 API
- login crawling
- correlation
- hadoop
- chatGPT
- flask
- integrated gradient
- session 유지
- youtube data
- TensorFlow
- 상관관계
- GCP
- grad-cam
- API Gateway
- BigQuery
- 공분산
- UDF
- subdag
- Counterfactual Explanations
- GenericGBQException
- API
- tensorflow text
- gather_nd
- airflow subdag
- top_k
- Airflow
- spark udf
- requests
- Retry
- Today
- Total
데이터과학 삼학년
SMOTENC :: oversampling with categorical variable 본문
Data imbalanced 데이터 불균형 문제에서 Oversampling을 많이들 사용한다.
카테고리컬 변수를 ovesampling할 수 있는 방법은 없을까?!
있다...!!!!
SMOTENC (numeric and categorical)!!!
>> SMOTE-NC for dataset containing numerical and categorical features.
단, categorical feature만 가진 데이터에는 사용할 수 없다
-> 다른 numeric variable의 값을 이용해 categorical variable을 증식시키는 알고리즘이기 때문!!!!
SMOTENC
- SMOTE"는 Synthetic Minority Over-sampling Technique의 약자이며,
- "NC"는 Nominal and Continuous features 의 약자
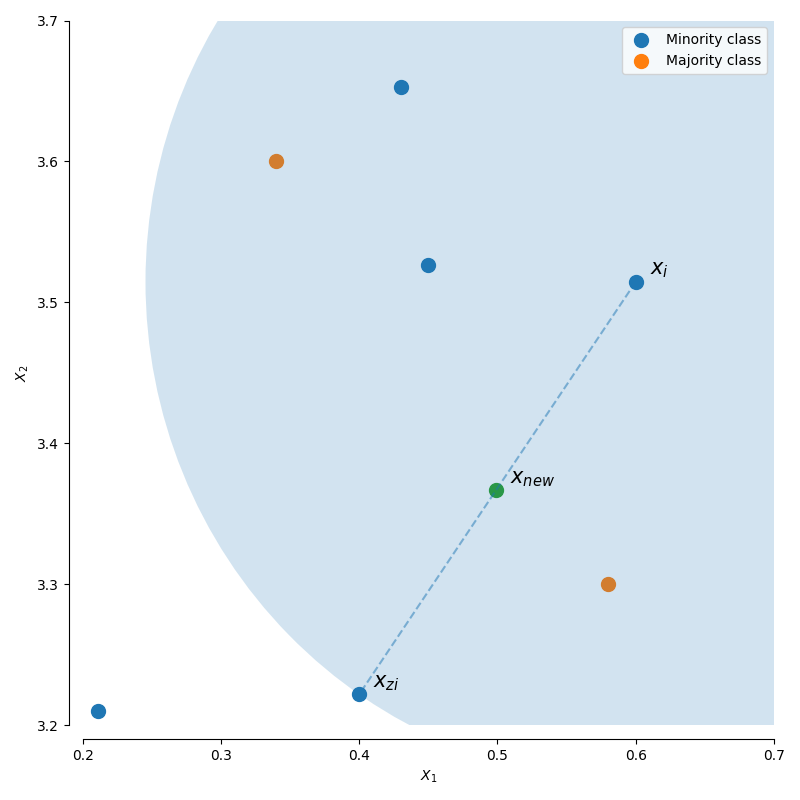
- SMOTE 방식으로 sample을 만들고 그룹핑한 후에 해당 그룹에 가까운 class의 category value를 붙이는 방식
코드
from collections import Counter
from numpy.random import RandomState
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTENC
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.1, 0.9], n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1, n_samples=1000, random_state=10)
print(f'Original dataset shape {X.shape}')
print(f'Original dataset samples per class {Counter(y)}')
# simulate the 2 last columns to be categorical features
X[:, -2:] = RandomState(10).randint(0, 4, size=(1000, 2))
sm = SMOTENC(random_state=42, categorical_features=[18, 19])
X_res, y_res = sm.fit_resample(X, y)
print(f'Resampled dataset samples per class {Counter(y_res)}')
참고
https://imbalanced-learn.org/stable/references/generated/imblearn.over_sampling.SMOTENC.html
SMOTENC — Version 0.11.0
[1] (1,2) N. V. Chawla, K. W. Bowyer, L. O.Hall, W. P. Kegelmeyer, “SMOTE: synthetic minority over-sampling technique,” Journal of artificial intelligence research, 321-357, 2002.
imbalanced-learn.org
SMOTE-NC in ML Categorization Models fo Imbalanced Datasets
Online Shoppers Purchasing Intention Categorization
medium.com
'Statistical Learning' 카테고리의 다른 글
| 카파 통계량 (Kappa-statistics) (0) | 2024.02.22 |
|---|---|
| 범주형 변수와 연속형 변수간 상관관계(categorical numerical correlation) (0) | 2023.09.25 |
| smoothing 기법 (0) | 2023.07.11 |
| pandas stratified sampling (층화표본) (0) | 2023.06.08 |
| 구조방정식(SEM ; structural equation modeling) 파이썬 코드 (0) | 2023.03.21 |


