
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- session 유지
- 상관관계
- Counterfactual Explanations
- XAI
- API
- integrated gradient
- airflow subdag
- GenericGBQException
- spark udf
- Retry
- API Gateway
- login crawling
- UDF
- BigQuery
- flask
- gather_nd
- subdag
- hadoop
- grad-cam
- tensorflow text
- TensorFlow
- chatGPT
- 공분산
- requests
- youtube data
- 유튜브 API
- correlation
- Airflow
- top_k
- GCP
- Today
- Total
데이터과학 삼학년
Apache Beam / Cloud Dataflow 본문
Apache Beam / Cloud Dataflow
- apache beam을 이용해서 pipeline을 구성할 수 있음
> realtime data → cloud pub/sub, batch data → cloud storage 데이터 공급받아옴
> GCP에서 apache beam을 위한 환경 → dataflow

> pCollection : 병렬 처리, 알아서 노드 형성하며 실행됨
- grep.py라는 파이썬파일로 pipeline을 구성(아래 그림은 아주 기초)

- 로컬 환경에서 실행하려면 그냥 실행시키면 되고, cloud dataflow에서 적용하고 싶으면 몇개 인자만 추가하여 실행 시키면 됨(아래 그림 참고)

- dataflow 구성하는 코드



- 아파치 빔~~~맵리듀스 기반으로 발전된 형태임

- mapping operation : 어떤 형태에 구약받지 않고 데이터를 가지고 오려면 flatmap은 하나의 큰 리스트로 형성하여 쓸 수 있음

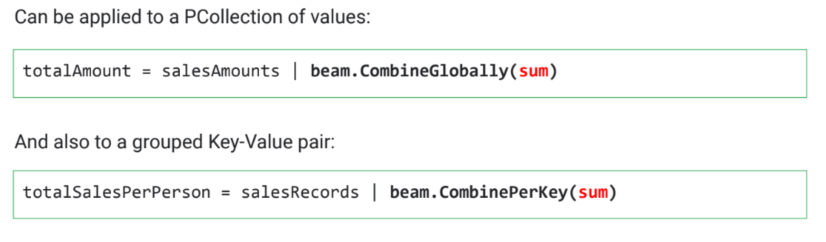
- reduce operation : Group by key를 통해 데이터의 결과를 가지고 와서 취합하는 단계
> combine key는 맵리듀스 알고리즘을 더 최적화할 수 있음 → aggregation 기능을 먼저 실행시켜 배치별 데이터를 나누고 취합
> group by key는 나중에 key별로 한번에 합치는 형태

groupby operation

combine operation
- 배치를 어떻게 나눌 것인가 결정 →windowinto : 스트림 데이터를 위한 !!!
> 120의 사이즈로 매 30초마다 새로운 배치를 만들 것

'Machine Learning' 카테고리의 다른 글
| Explore and Creating the Dataset (0) | 2020.02.03 |
|---|---|
| Preprocessing and feature creations (with Cloud Dataprep) (0) | 2020.02.03 |
| Custom Estimator, Keras (0) | 2020.01.18 |
| Hyperparameter Tuning (1) | 2020.01.18 |
| Dropout (0) | 2020.01.18 |



