
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- gather_nd
- requests
- flask
- Airflow
- grad-cam
- login crawling
- XAI
- GenericGBQException
- spark udf
- 상관관계
- subdag
- hadoop
- BigQuery
- chatGPT
- 공분산
- GCP
- top_k
- session 유지
- Retry
- tensorflow text
- TensorFlow
- UDF
- airflow subdag
- integrated gradient
- API Gateway
- youtube data
- Counterfactual Explanations
- API
- 유튜브 API
- correlation
- Today
- Total
데이터과학 삼학년
PU Learning : Positive-Unlabeled Learning 본문
PU Learning : Positive-Unlabeled Learning
개요
- 일반적으로 이진분류문제에서 도전적인 것은 아마 negotive label data를 가지고 있지 않는 문제임
- 이러한 이슈는 주로 imbalanced dataset에 대한 해결과제에서도 동반되는 문제임
- 단순히 unknown set을 sampling해서 처리하기도 하지만, 이러한 방법은 unknownset에 대한 오염이 발생하고, classifier 모델도 제대로 학습되지 않는 문제가 발생함
PU Learning
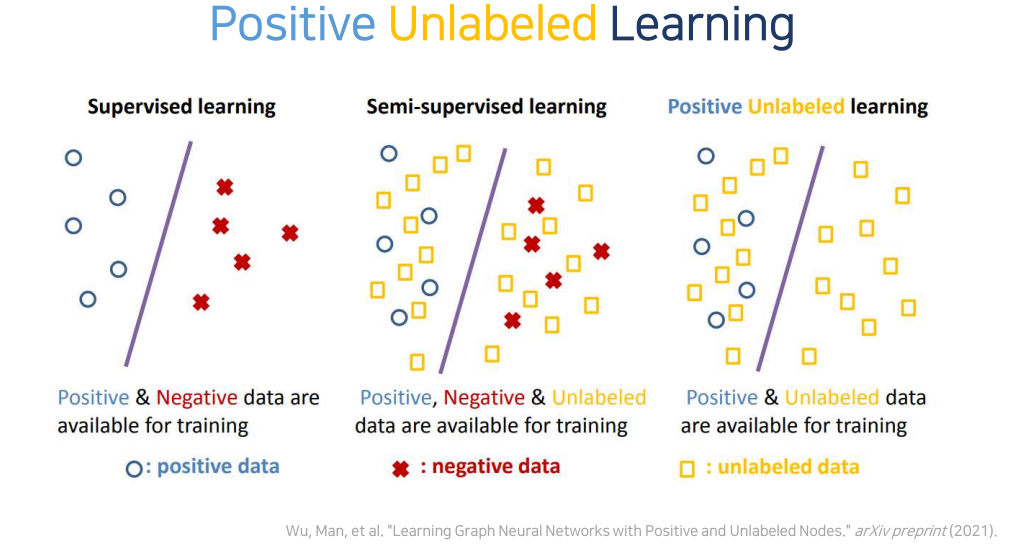
- 기계학습은 학습데이터(방법)에 따라 supervised, unsupervised, semi-supervised로 나눌 수 있음
- supervised learning은 PN learning 이라고도 불리며, 모든 데이터에 label이 부여된 경우 가능함
- 하지만, 모든 데이터에 positive나 negative로 붙이는 건 어려움
- 한 예로 이상현상이 일어났던 시점에 해당 데이터가 이상하다라고 판단할 수 있지만, 이상현상이 일어나지 않았던 시점에 해당 데이터가 모두 정상이라고 말하기는 어려움
- 즉, unlabeled 데이터는 잠재적인 positive, negative 성격을 가지고 있기때문에 이를 고려해서 좀 더 정교하게 machine을 학습 시킬 필요가 있음
PU Learning Method
Original approach (2002-3)
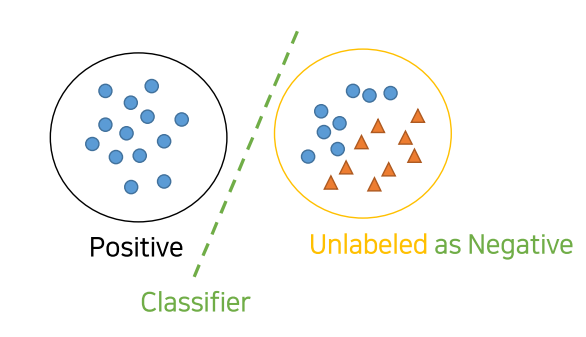
1. 모든 Unlabeld dataset을 negative로 취급하여 P vs N를 분류하는 clf 모델 학습
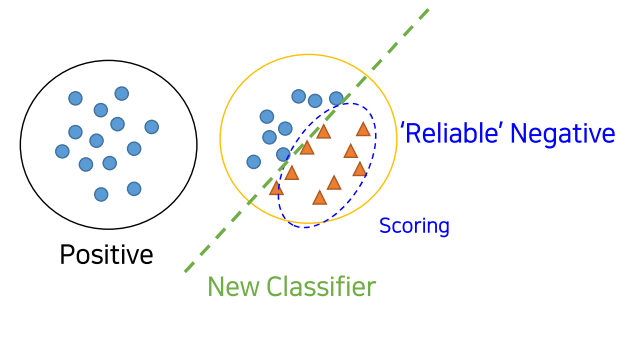
2. 1에서 학습한 clf를 이용하여 Unlabed(unknown class) dataset를 scoring하고, reliable negatives(RN) set을 만듦(비교적 Negotive에 가까운 점수를 가진 애들을 분리)

3. P vs RN을 분류하는 clf 모델을 학습시킴. 그리고 남아 있던 Unlabeled dataset(즉, 2에서 Negative에 가깝다고 나오지 않은)을 scoring매기고, 추가적으로 RN에 가까운지 먼지를 측정하여 분류
4. 3의 과정을 계속적으로 수렴할때까지 반복(iterative)
Modified approach (Fusilier et al. 2014)
1. 모든 Unlabeld dataset을 negative로 취급하여 P vs N를 분류하는 clf 모델 학습
2. 1에서 학습한 clf를 이용하여 Unlabed(unknown class) dataset를 scoring하고, reliable negatives(RN) set을 만듦(비교적 Negotive에 가까운 점수를 가진 애들을 분리)
3. P vs RN을 분류하는 clf 모델을 학습시킴. 그리고 남아 있던 Unlabeled dataset(즉, 2에서 Negative에 가깝다고 나오지 않은)을 scoring매기고, 추가적으로 RN에 가까운지 먼지를 측정하는데, 여기서 RN 중 Positives와 가깝다고 scoring된 것들은 제외시켜 버림
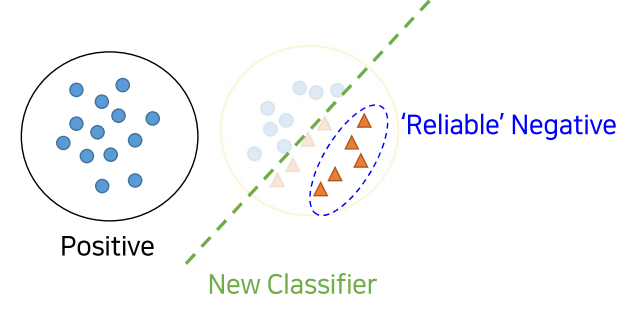
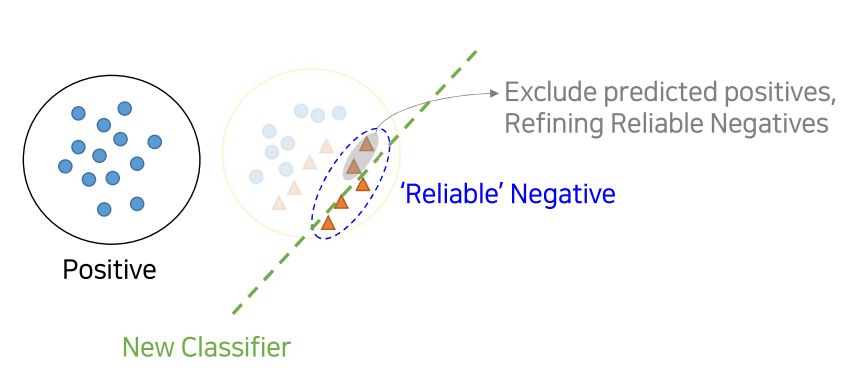
4. 3의 과정을 계속적으로 수렴할때까지 반복(iterative)
참조
https://towardsdatascience.com/pu-learning-e2059f4f9b52
PU Learning
A challenge that keeps presenting itself at work is one of not having a well labelled set of negative cases in the context of needing to…
towardsdatascience.com
https://www.youtube.com/watch?v=_1dcfeq4iN8
'Machine Learning' 카테고리의 다른 글
| tensorflow_decision_forests 를 이용해서 손쉽게 RandomForest, GBM 사용하기 (0) | 2022.06.28 |
|---|---|
| LOF (Local Outlier Factor) (0) | 2022.06.04 |
| Graph Neural Network (0) | 2022.05.16 |
| Knowledge Distillation (0) | 2022.04.22 |
| Feature importance (in Decision Tree, RF) (0) | 2022.04.18 |



