
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- tensorflow text
- GenericGBQException
- session 유지
- TensorFlow
- Counterfactual Explanations
- UDF
- hadoop
- login crawling
- API
- grad-cam
- 공분산
- spark udf
- airflow subdag
- 상관관계
- GCP
- Airflow
- flask
- youtube data
- correlation
- BigQuery
- subdag
- requests
- API Gateway
- gather_nd
- top_k
- XAI
- integrated gradient
- Retry
- 유튜브 API
- chatGPT
- Today
- Total
데이터과학 삼학년
Knowledge Distillation 본문
Knowledge Distillation
- 복잡한 딥러닝 모델을 경량화된 디바이스에서 사용할때 보다 낮은 메모리를 사용하면서, 정확도는 어느 수준 이상인 모델이 필요함
- 복잡한 딥러닝 모델 (teacher model)은 많은 수의 파라미터를 가지고 있다. 이러한 학습치(지식)를 경량화 모델(student model)에 전달해주는 즉, transfer해주는 개념
- 즉, 높은 정확도를 갖는 딥러닝 모델을 이용해, Teacher 모델의 loss function과 student model의 loss function을 결합시킨 distillation loss+Student model loss를 최소로 하도록 student model을 학습시키면 경량화 모델일지라도, 복잡한 모델의 일부 지식을 넘겨받아 비교적 정확성이 보완된 경량화 모델을 얻을 수 있다는 아이디어
- 먼저 배워서 나중에 지식을 전파해주는 과정이 선생님과 학생의 관계와 비슷하여 Teacher, Student model이라 지칭하는 것 같다는 의견도 있음

Knowledge Distillation 철학
Model knowldege
- 어떠한 이미지를 분류하는 모델이 있다고 가정하자.
- 모델은 softmax를 이용하여 각 label별 확률값을 추출하게 되는데, 여기서 모델의 output이 dog였다면, dog외의 나머지 label에 대해 예측한 정보. 즉, 개를 제외한 나머지 label 고양이, 사자, 소 중에 어떠한 부분에 더 가깝게 예측했는지 확인할 수 있다. 이러한 출력값들이 모델의 knowledge 지식이라고 볼 수 있다.
-> 즉 결과값에 대해 모델이 label별 예측한 정보를 토대로 정보를 알 수 있고, 1순위 예측값 외 2, 3순위에 대한 예측값에 어느정도의 크기를 부여했는지 확인하는 것이 modeld의 knowledge라는 것

Temperature
- model이 예측한 정보를 토대로 지식을 얻으려하지만, softmax를 이용하면 1순위외 2,3순위의 값들은 매우 작은 값을 갖게 된다.
- 이를 보정하기 위해 일반 소프트맥스값을 쓰는 것이 아니라 각 노드의 최종 출력값에 T(temperature)라는 값을 나눈 값에 대한 softmax를 이용하여 보다 지식을 확인하기 좋게 만드는 개념 (soft label)


- 결국 이 온도(Temperature)라는 설정때문에 Distillation(증류)라는 얘기가 나옴
Distillation Loss
- Teacher model의 knowledge를 어떻게 Student model에 전달할 수 있을까?
- Teacher model을 학습시킨후 그 결과를 이용한 loss function을 만들어 Student model이 해당 loss function을 이용하여 학습할 수 있도록 한다.
- 여기서 distillation loss function이 바로 Teacher model의 knowledge를 Student model에게 전달시키는 역할을 한다고 볼 수 있음
- Student모델은 loss function으로 [distillation loss + CE loss] 를 이용하여 학습되게 만들어주고, Student모델은 모델의 구성 자체가 경량화로 만들었기 때문에, 학습모델을 device에 적용할 수 있음

Knowledge Distillation 구조
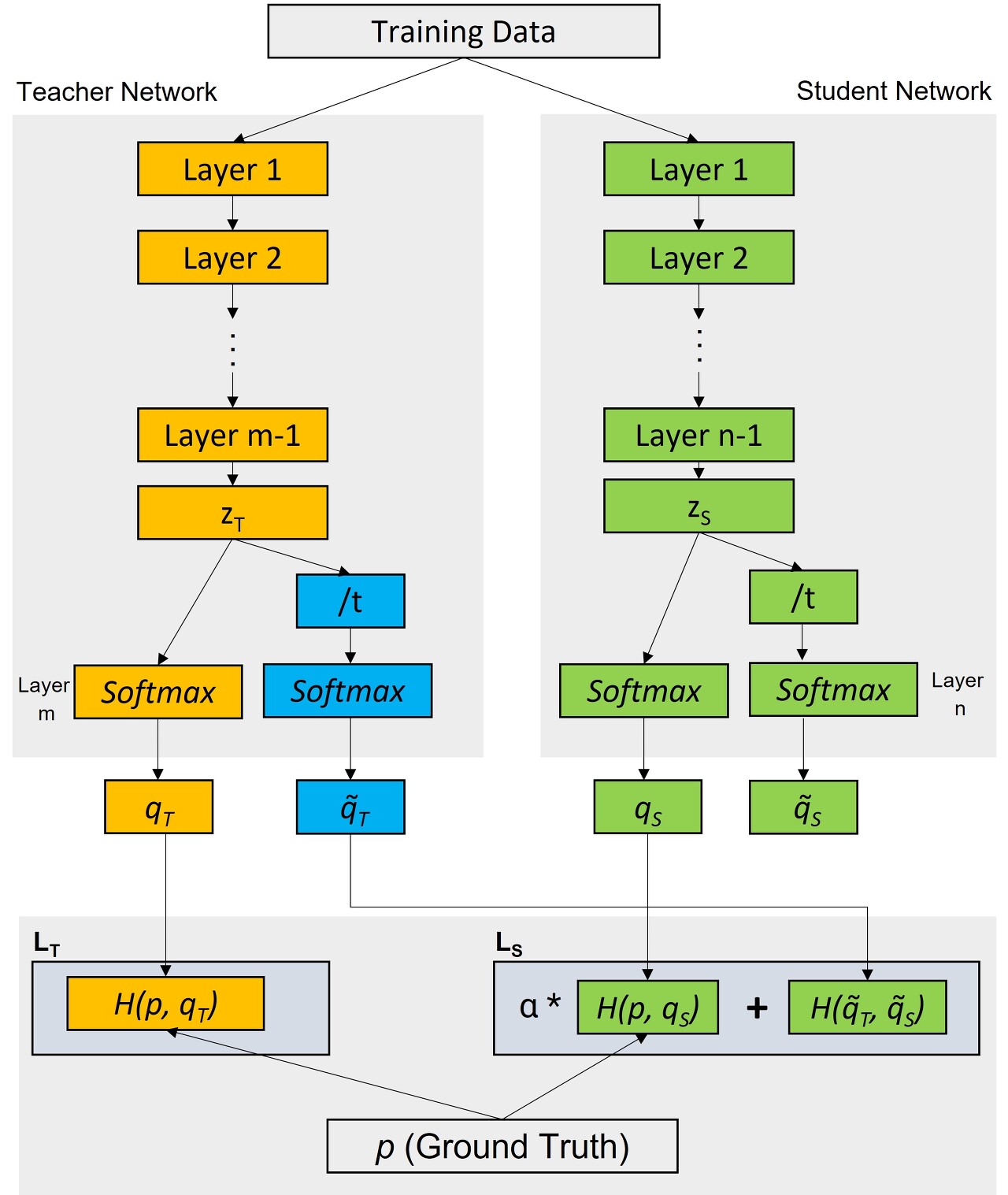
|
Loss Functions for teacher and student networks are defined as below:
Teacher Loss LT: (between actual lables and predictions by teacher network)
LT = H(p,qT)
Total Student Loss LTS :
LTS = α * Student Loss + Distallation Loss
LTS = α* H(p,qs) + H(q̃T, q̃S)
Where,
Distillation Loss = H(q̃T, q̃S)
Student Loss = H(p,qS)
Here:
H : Loss function (Categorical Cross Entropy or KL Divergence)
zT and zS : pre-softmax logits
q̃T : softmax(zT/t)
q̃S: softmax(zS/t)
alpha (α) and temperature (t) are hyperparameters.
Temperature t is used to reduce the magnitude difference among the class likelihood values.
|
참조
Knowledge Distillation: Theory and End to End Case Study
This article talks about implementation on a business problem to classify x-ray images for pneumonia detection.
www.analyticsvidhya.com
https://baeseongsu.github.io/posts/knowledge-distillation/
딥러닝 모델 지식의 증류기법, Knowledge Distillation
A minimal, portfolio, sidebar, bootstrap Jekyll theme with responsive web design and focuses on text presentation.
baeseongsu.github.io
'Machine Learning' 카테고리의 다른 글
| PU Learning : Positive-Unlabeled Learning (0) | 2022.05.20 |
|---|---|
| Graph Neural Network (0) | 2022.05.16 |
| Feature importance (in Decision Tree, RF) (0) | 2022.04.18 |
| Transfer learning / Fine tuning (0) | 2022.01.21 |
| Fine tuning (0) | 2022.01.19 |



