
250x250
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- TensorFlow
- 유튜브 API
- session 유지
- GCP
- API Gateway
- API
- XAI
- subdag
- 상관관계
- 공분산
- correlation
- integrated gradient
- GenericGBQException
- UDF
- Retry
- gather_nd
- spark udf
- login crawling
- airflow subdag
- youtube data
- grad-cam
- BigQuery
- Airflow
- Counterfactual Explanations
- top_k
- hadoop
- flask
- chatGPT
- requests
- tensorflow text
Archives
- Today
- Total
데이터과학 삼학년
Learning rate and Batch size 본문
반응형
Learning rate and Batch size
- learning rate 는 최적화를 위해 어느 정도의 step size를 가질 것이냐 결정
> 너무 작으면 training이 오래 걸릴 것이요, 너무 크면 학습이 잘되지 않을 것임
> 보통 0.2보다 작은 값이나 1 / (sqrt(feature 개수)) 로 정함

- batch size가 너무 작으면 training 하기에 적합한 데이터 셋이 없을 수 있음 → 그래디언트를 계산할 샘플수
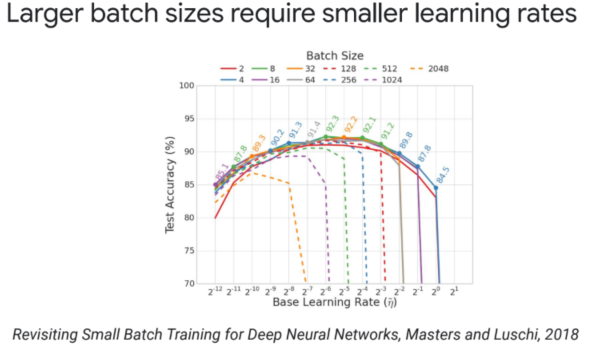
>> batch size가 크면 learning rate를 작게 줄이는 것이 실험적으로 좋다는 논문
728x90
반응형
LIST
'Machine Learning' 카테고리의 다른 글
| Dropout (0) | 2020.01.18 |
|---|---|
| Optimization (0) | 2020.01.18 |
| Regularization (0) | 2020.01.18 |
| Feature engineering 기초 & wide and deep model (0) | 2020.01.18 |
| Distributed training (feat.GCP CMLE) (0) | 2020.01.12 |
'Machine Learning' Related Articles
more




Comments