
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 상관관계
- TensorFlow
- UDF
- grad-cam
- youtube data
- gather_nd
- chatGPT
- session 유지
- 공분산
- correlation
- requests
- 유튜브 API
- subdag
- login crawling
- BigQuery
- integrated gradient
- Airflow
- API Gateway
- GenericGBQException
- top_k
- Retry
- flask
- Counterfactual Explanations
- airflow subdag
- API
- hadoop
- spark udf
- XAI
- GCP
- tensorflow text
- Today
- Total
데이터과학 삼학년
모델 추정과 차수 선택 (퍼옴) 본문
최대 가능도 추정
모델의 차수를 찾은 다음(즉, p, d, q 값), 다음과 같은 매개변수 c, , 을 추정할 필요가 있습니다.
R에서 ARIMA 모델을 계산할 때는, 최대 가능도 추정(maximum likelihood estimation) (MLE)을 사용합니다.
이 방법은 관찰한 데이터를 얻는 확률을 최대화하는 매개변수의 값을 찾습니다.
ARIMA 모델에서는 MLE는 다음과 같은 양을 최소화하는 최소제곱(least squares) 추정과 비슷합니다.

(5 장에서 다룬 회귀 모델에서, MLE는 최소제곱추정(least squares estimation)과 정확하게 같은 매개변수 추정값을 냅니다.)
ARIMA 모델이 회귀 모델을 추정하는 것보다 훨씬 더 복잡하고, 서로 다른 소프트웨어가 서로 다른 추정 기법과 최적화 알고리즘을 사용하기 때문에 살짝 다른 결과를 낼 수 있다는 것에 주목하시길 바랍니다.
실제로는, R은 데이터의 로그 가능도(log likelihood) 값을 알려줄 것입니다.
즉, 추정한 모델에서 나온 관측 데이터의 확률의 로그를 말합니다.
주어진 , d, q 값에 대해, 매개변수값을 찾을 때, 로그 가능도를 최대화할 것입니다.
정보 기준
회귀에서 예측변수(predictor)를 고를 때 유용했던
아카이케(Akaike)의 정보 기준(AIC; Akaike’s information Criterion)이 ARIMA 모델에서 차수를 결정할 때도 유용합니다.
AIC는 다음과 같이 쓸 수 있습니다.

여기에서 은 데이터의 가능도, 면 이고, 이면 입니다.
괄호 안의 마지막 항이 (와 잔차(residual)의 분산을 포함하는) 모델의 매개변수 개수라는 것에 주목하시길 바랍니다.
ARIMA 모델에 대해, 수정된 AIC는(AICc) 다음과 같이 쓸 수 있습니다.
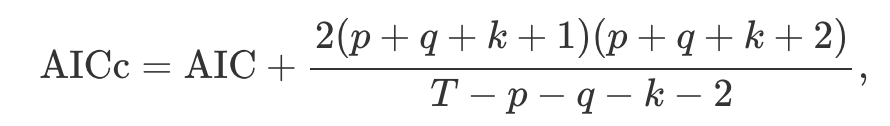
베이지안(Bayesian) 정보 기준은 다음과 같이 쓸 수 있습니다.

AIC, AICc, 또는 BIC를 최소하하여 좋은 모델을 얻습니다.
여기에서는 AICc를 사용하겠습니다.
이러한 정보 기준이 모델의 적절한 차분 차수(d)를 고를 때 별로 도움이 되지 않는 경향이 있고,
와 값을 고를 때만 도움이 된다는 것은 중요한 점입니다.
차분을 구하는 것을 통해 가능도(우도; likelihood)를 계산하는 데이터가 바뀌기 때문에,
서로 다른 차수로 차분을 구한 모델의 AIC 값을 비교할 수 없게 됩니다.
그래서 d를 고르기 위해 다른 방법을 사용해야 하고, 그리고 나서 와 를 고르기 위해 AICc를 사용할 수 있습니다.
참조: otexts.com/fppkr/arima-estimation.html
Forecasting: Principles and Practice
2nd edition
Otexts.com
'Time Series Analysis' 카테고리의 다른 글
| 시계열 데이터 분석 기초 (5) | 2024.10.25 |
|---|---|
| Dynamic Time Warping(DTW) (0) | 2022.03.25 |
| VAR (Vector Auto Regression) - 다변량 시계열 분석 (0) | 2021.02.01 |
| Multivariate 시계열 데이터 LSTM 적용 케이스 예시 (3) | 2021.01.06 |
| [RPs] 시계열 데이터 이미지화 (1) | 2021.01.04 |


