
250x250
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- login crawling
- GCP
- XAI
- UDF
- 유튜브 API
- chatGPT
- Airflow
- grad-cam
- requests
- GenericGBQException
- youtube data
- session 유지
- correlation
- gather_nd
- integrated gradient
- API Gateway
- subdag
- top_k
- 공분산
- flask
- Retry
- Counterfactual Explanations
- 상관관계
- API
- TensorFlow
- spark udf
- airflow subdag
- BigQuery
- tensorflow text
- hadoop
Archives
- Today
- Total
데이터과학 삼학년
Multivariate 시계열 데이터 LSTM 적용 케이스 예시 본문
반응형
Many To One - single output
- 한개 기간이 들어가서 한개 기간 결과 출력
- output의 갯수가 single(1개)
- 엄밀히 말하면, 바로 직전 시간대 한개가 들어가 다음 시간대 한개를 예측하는 것이므로 OneToOne 으로 볼 수 있지만, multivariate이기 때문에 ManyToOne으로 보았음
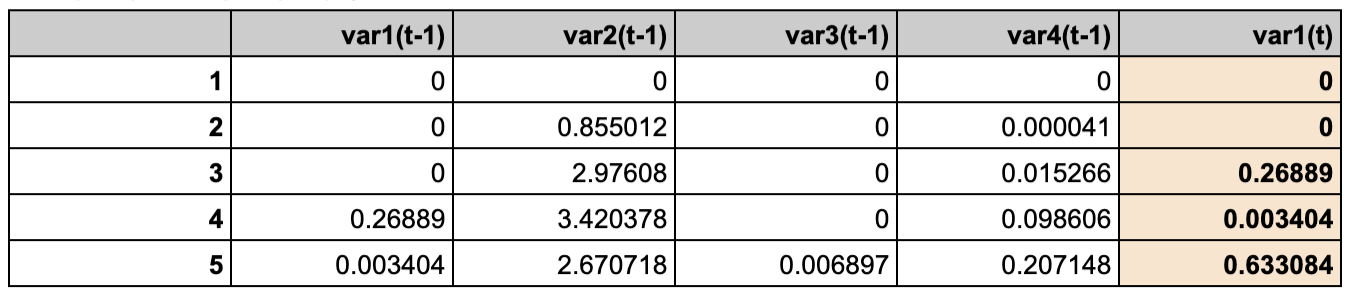
- 예측결과와 실제값 비교 (4개 feature 로 1개 feature 예측)
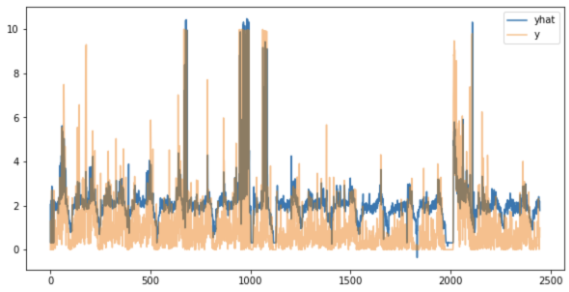
Many To Many - multi output
- 한개 기간이 들어가서 한개 기간 결과 출력
- output의 갯수가 multi(2개 이상)

- 예측결과와 실제값 비교 (4개 feature 로 4개 feature 예측)
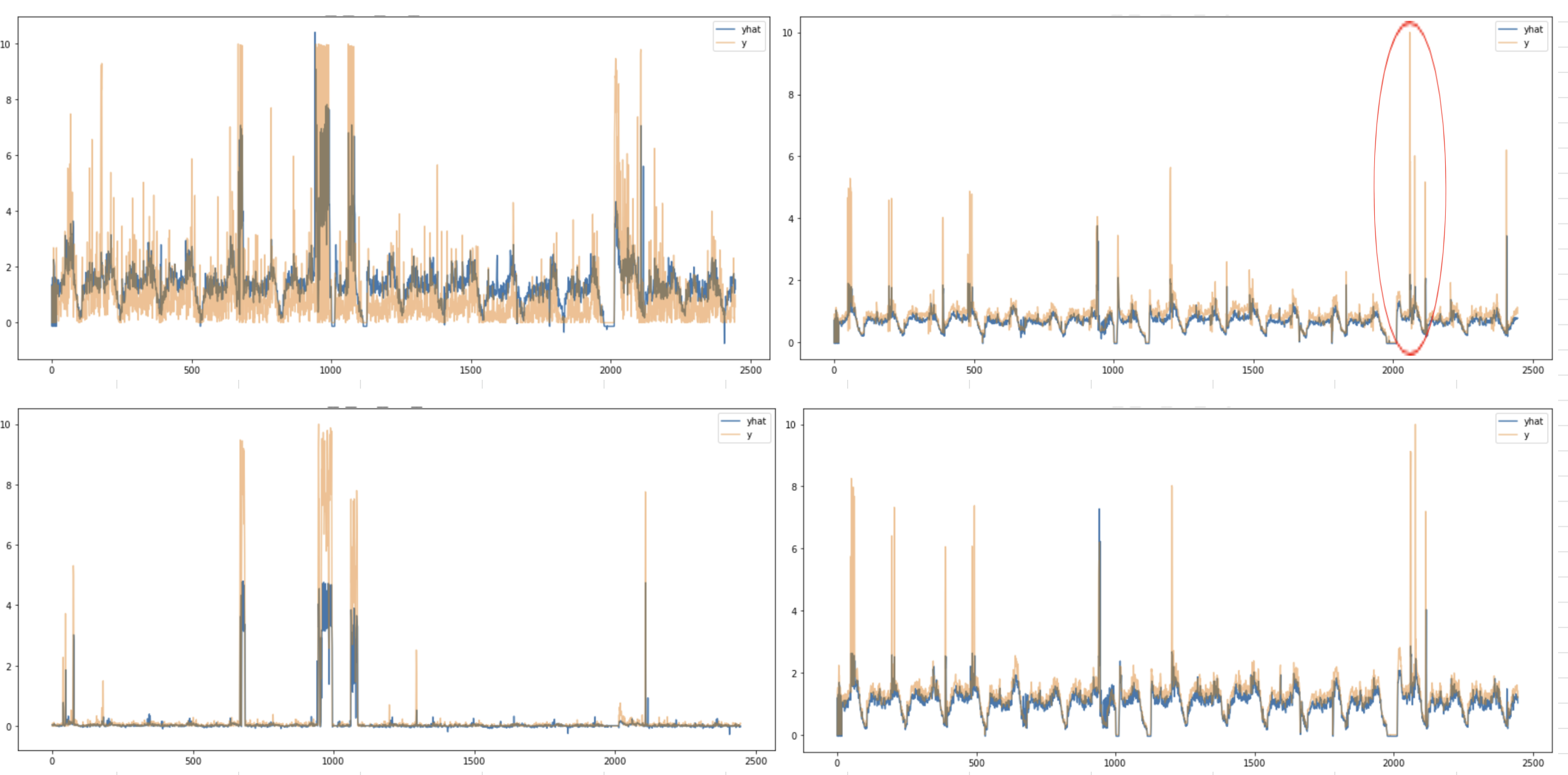
Many To One - multi output
- 여러 기간이 들어가서 한개 기간 결과 출력
- output의 갯수가 multi(2개 이상)

- 예측결과와 실제값 비교 (4개 feature 로 4개 feature 예측)
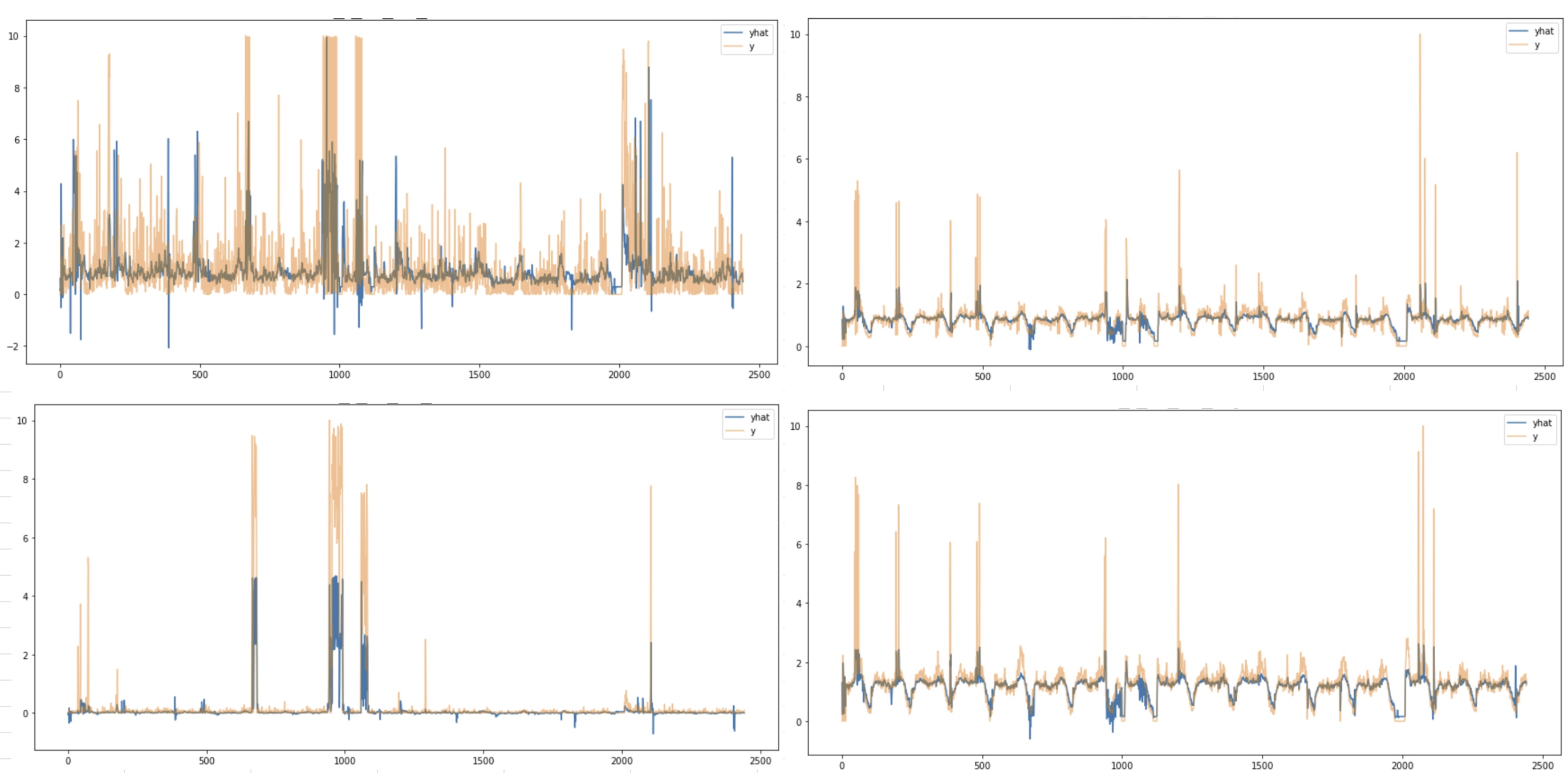
시계열 예측모델을 이용해 이상치를 잡는 다는 개념으로 보았을때, 시계열적으로 이상치를 잡을 수 있다는 이점이 있음
- multivariate timeseries 모델이므로, 서로 상관이 있는 feature간의 관계가 고려됨
- 즉, 1번 feature가 정상적인 패턴일때, 2번 feature의 비이상적 변화 탐지에 유리
- 한계 : 예측모델이므로, feature의 값에 따라 높은 값을 가질 수 있어 실제 이상치인지 아닌지는 feature간 관계를 통해서만 파악할 수 있음
# prepare data for lstm
from pandas import read_csv
from pandas import DataFrame
from pandas import concat
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# convert series to supervised learning
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i >= 0:
names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
# else:
# names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
# load dataset
dataset = read_csv('data.csv', header=0, index_col=0)
values = dataset.values
# integer encode direction
encoder = LabelEncoder()
values[:,0] = encoder.fit_transform(values[:,0])
# ensure all data is float
values = values.astype('float32')
# normalize features
scaler = MinMaxScaler(feature_range=(0, 10))
# scaler = StandardScaler()
scaled = scaler.fit_transform(values)
# frame as supervised learning
reframed = series_to_supervised(scaled, 4, 1)
# reframed = series_to_supervised(values, 1, 1)
# drop columns we don't want to predict
# reframed.drop(reframed.columns[[5,6,7]], axis=1, inplace=True)
print(reframed.head()) # 4개 변수로, get_ether 추정
var1(t-4) var2(t-4) var3(t-4) var4(t-4) var1(t-3) var2(t-3) \
4 0.000000 0.000000 0.000000 0.000000 0.000000 0.855012
5 0.000000 0.855012 0.000000 0.000041 0.000000 2.976080
6 0.000000 2.976080 0.000000 0.015266 0.268890 3.420378
7 0.268890 3.420378 0.000000 0.098606 0.003404 2.670718
8 0.003404 2.670718 0.006897 0.207148 0.633084 2.425154
var3(t-3) var4(t-3) var1(t-2) var2(t-2) var3(t-2) var4(t-2) \
4 0.000000 0.000041 0.000000 2.976080 0.000000 0.015266
5 0.000000 0.015266 0.268890 3.420378 0.000000 0.098606
6 0.000000 0.098606 0.003404 2.670718 0.006897 0.207148
7 0.006897 0.207148 0.633084 2.425154 0.000000 0.258438
8 0.000000 0.258438 0.435671 2.401715 0.000000 0.260164
var1(t-1) var2(t-1) var3(t-1) var4(t-1) var1(t) var2(t) var3(t) \
4 0.268890 3.420378 0.000000 0.098606 0.003404 2.670718 0.006897
5 0.003404 2.670718 0.006897 0.207148 0.633084 2.425154 0.000000
6 0.633084 2.425154 0.000000 0.258438 0.435671 2.401715 0.000000
7 0.435671 2.401715 0.000000 0.260164 0.432267 2.504311 0.000000
8 0.432267 2.504311 0.000000 0.331470 0.122532 2.353095 0.000000
var4(t)
4 0.207148
5 0.258438
6 0.260164
7 0.331470
8 0.362599# split into train and test sets
values = reframed.values
n_train_hours = 24 * 6 * 28 # 4주
train = values[:n_train_hours, :]
test = values[n_train_hours:, :]
# split into input and outputs
train_X, train_y = train[:, :-4], train[:, -4:]
test_X, test_y = test[:, :-4], test[:, -4:]
# reshape input to be 3D [samples, timesteps, features]
train_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1]))
test_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1]))
print(train_X.shape, train_y.shape, test_X.shape, test_y.shape)
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
from tensorflow.keras import optimizers
# design network
learning_rate=0.01
model = Sequential()
model.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dense(100))
model.add(Dense(4))
model.compile(optimizer=optimizers.Adam(learning_rate=learning_rate), loss='mae')
# fit network
history = model.fit(train_X, train_y, epochs=50, batch_size=16, validation_data=(test_X, test_y), verbose=2, shuffle=False)
# plot history
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='test')
pyplot.legend()
pyplot.show()from ipywidgets import interact
feature_dic = {ind:i for ind, i in enumerate(features)}
def compare_plot(feature_n):
pyplot.figure(figsize=(15,7))
pyplot.title(feature_dic[feature_n])
pyplot.plot(yhat[:,feature_n],label='yhat')
pyplot.plot(test_y[:,feature_n],alpha=0.5,label='y')
# pyplot.plot(resid,label='resid',alpha=0.3)
pyplot.legend()
interact(compare_plot,feature_n=[0,1,2,3])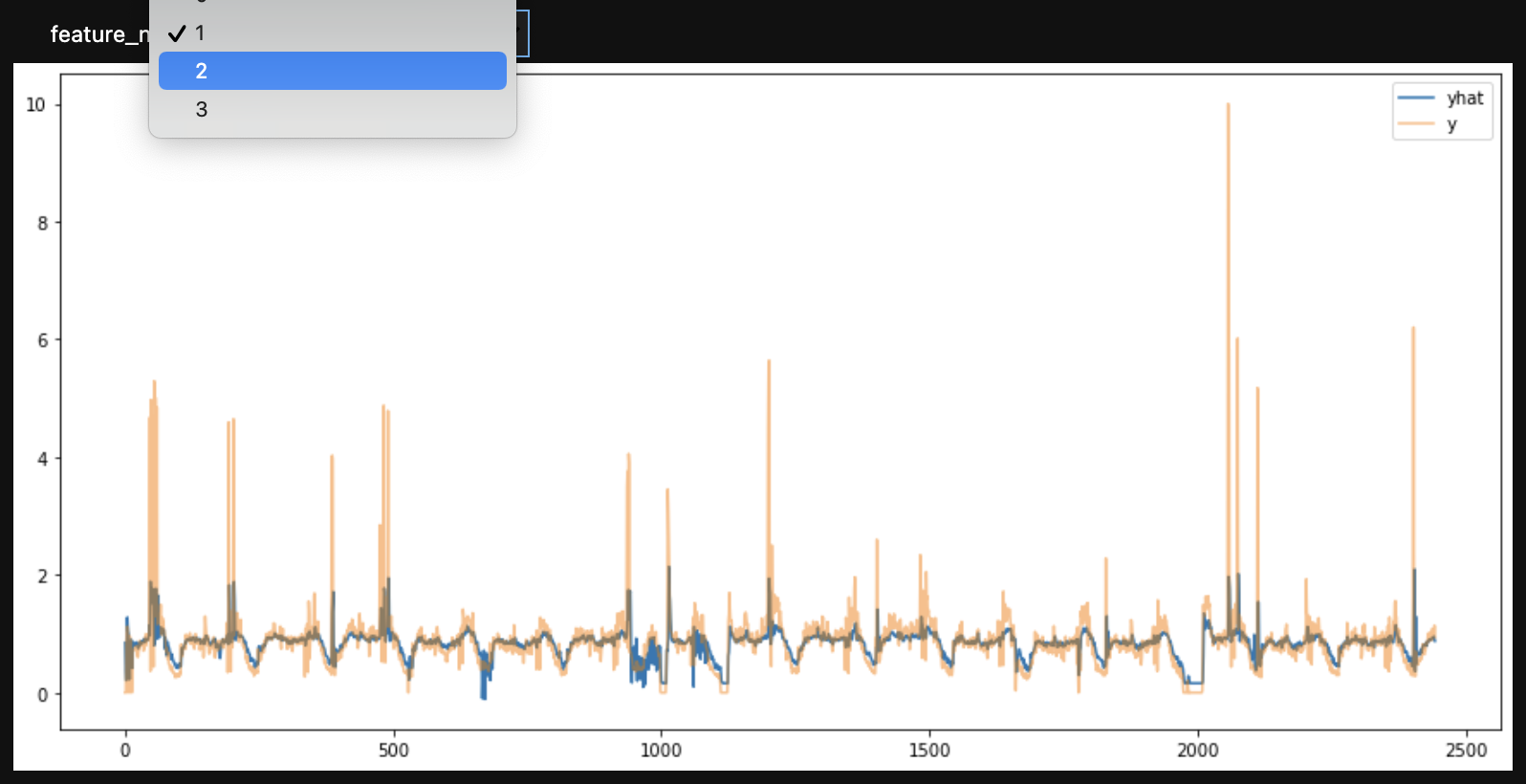
728x90
반응형
LIST
'Time Series Analysis' 카테고리의 다른 글
| 모델 추정과 차수 선택 (퍼옴) (0) | 2021.02.01 |
|---|---|
| VAR (Vector Auto Regression) - 다변량 시계열 분석 (0) | 2021.02.01 |
| [RPs] 시계열 데이터 이미지화 (0) | 2021.01.04 |
| Recurrence Plot (feat. pyts - Imaging time series) (0) | 2020.12.18 |
| Prophet for python (feat. fbprophet) (0) | 2020.12.14 |
'Time Series Analysis' Related Articles
more



Comments