
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 상관관계
- requests
- Airflow
- 공분산
- XAI
- flask
- chatGPT
- youtube data
- correlation
- Retry
- session 유지
- GenericGBQException
- gather_nd
- Counterfactual Explanations
- 유튜브 API
- spark udf
- hadoop
- subdag
- API Gateway
- airflow subdag
- integrated gradient
- BigQuery
- grad-cam
- API
- GCP
- top_k
- tensorflow text
- TensorFlow
- login crawling
- UDF
- Today
- Total
데이터과학 삼학년
PCA (Principal Component Analysis) - 주성분 분석 본문
PCA (주성분 분석)은 가장 흔히 쓰이는 차원 축소 방법이다.
원리
- 데이터에 가장 가까운 초평면 (hyperplane)을 정의한 다음, 해당 평면에 투영(projection)시키는 방법
>> 공분산(편차) 매트릭스를 고유값 분해하여 주성분 행렬을 구하고, 줄이고자하는 차원 수(d)만큼의 주성분 행렬의 열을 곱하여 투영시키는 방법
분산 보존
- 저차원의 초평면에 데이터셋을 투영하기전에 올바른 초평면을 정의하는 것이 중요하다.
- 아래 그림처럼 분산을 최대로 유지하는 축을 찾는다 --> 이 선택은 원본 데이터셋과 투영된 것 사이의 평균 제곱 거리를 최소화하는축이라 할 수 있다.
- 분산을 최대로 보존한다 --> 정보의 손실을 최소화한다.

주성분
- 주성분은 데이터셋에서 분산을 최대인 축을 찾는 과정을 말한다.
먼저 데이터셋에 가장 분산을 최대한 축을 찾고, 그다음은 찾은 최대축에 직교하고, 최대한 분산을 보존하는 두번째 축을 찾고, 또 그다음 세번째 축을 찾는 방법을 말한다.
즉, 고차원 데이터의 경우, 차원의 수만큼 i번째 주성분 축을 찾을 수 있다.
>> i번째 축을 이 데이터의 i번째 주성분(principal component) 라고 함
주성분을 찾는 방법
- 특이값 분해(singular value decomposition) 을 통해 찾을 수 있다.
- 훈련 세트 행렬 X가 있다면, X를 특이값 분해하면, U, V를 찾을 수 있는데,
여기서, V가 바로 주성분 행렬이 된다.

V =( pc1, pc2, ..., pcn)
import numpy as np
X = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
X_centered = X - X.mean(axis=0)
U,s,Vt = np.linalg.svd(X_centered)
c1 = Vt.T[:,0]
c2 = Vt.T[:,1]
print('X_centered:',X_centered)
print('V:',Vt.T)
print('c1:',c1)
print('c2:',c2)
=======
X_centered:
[[-3. -3. -3.]
[ 0. 0. 0.]
[ 3. 3. 3.]]
V:
[[ 0.57735027 -0.81649658 0. ]
[ 0.57735027 0.40824829 -0.70710678]
[ 0.57735027 0.40824829 0.70710678]]
c1:
[0.57735027
0.57735027
0.57735027]
c2:
[-0.81649658
0.40824829
0.40824829]
=======
X.mean(axis=0)
array([4., 5., 6.])
d차원으로 투영하기
- SVD를 이용해서 구한 주성분 행렬을 이용해 축소하기 원하는 차원(d) 만큼 열을 곱(행렬곱)하면 된다.
>> Xd = X*Wd
W2 = Vt.T[:,:2]
W2
===
array([[ 0.57735027, -0.81649658],
[ 0.57735027, 0.40824829],
[ 0.57735027, 0.40824829]])
X2d = X_centered.dot(W2)
X2d
===
array([[-5.19615242e+00, -3.33066907e-16],
[ 0.00000000e+00, 0.00000000e+00],
[ 5.19615242e+00, 3.33066907e-16]])
설명된 분산의 비율
- expained variance ratio 를 통해 우리는 차원을 줄였을 때, 얼만큼의 데이터 정보를 보존할지 정할 수 있다.
> 분산 비율이 클 수록 정보 손실이 작은 것
pca.explained_variance_ratio_
#===
array([0.8424,0.1463])
적절한 차원수 선택하기
- 축소할 차원 수를 임의로 정하기 보다, 충분한 분산이 될때까지 더해야할 차원수를 선택하는 것이 훨씬 이상적
pca = PCA()
pca.fit(X_train)
cumsum = np.cumsum(pca.explained_variance_ratio_)
d = np.argmax(cumsum >= 0.95) + 1- n_components 를 이용하여, 보존하길 원하는 분산을 설정할 수 있다.
pca = PCA(n_components=0.95)
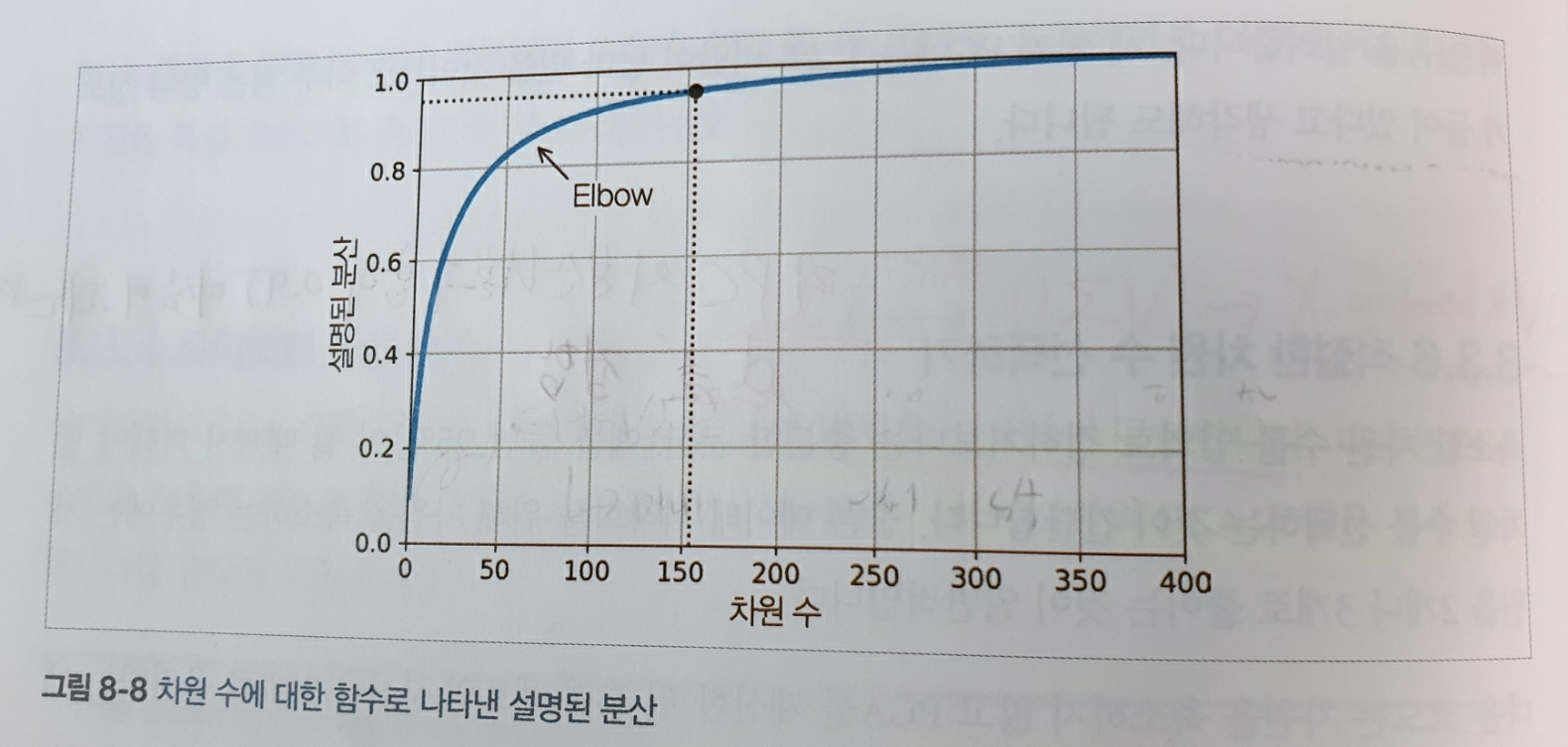
X_reduced = pca.fit_transform(X_train)- 또 다른 방법은 설명된 분산을 차원수에 대한 함수로 그려 elbow 선택법을 이용하여 선택하는 방법
'Machine Learning' 카테고리의 다른 글
| Autoencoder 를 이용한 차원 축소 (latent representation) (0) | 2021.03.03 |
|---|---|
| PCA (Principal Component Analysis) 종류 (0) | 2021.02.02 |
| Batch normalization 적용으로 train set 데이터의 정규화 대체! (0) | 2021.01.08 |
| [Clustering] DBSCAN (0) | 2021.01.01 |
| Anomaly Detection 종류(Point, Contextual, Collective) (0) | 2020.12.01 |


