
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- hadoop
- tensorflow text
- requests
- grad-cam
- top_k
- airflow subdag
- GCP
- session 유지
- login crawling
- API
- TensorFlow
- youtube data
- spark udf
- XAI
- chatGPT
- 공분산
- gather_nd
- UDF
- flask
- GenericGBQException
- 상관관계
- Counterfactual Explanations
- correlation
- Retry
- 유튜브 API
- integrated gradient
- Airflow
- API Gateway
- subdag
- BigQuery
- Today
- Total
데이터과학 삼학년
[Clustering] DBSCAN 본문
DBSCAN : 밀도기반의 클러스터링 기법
-> knn, k-means의 경우, 각 데이터 별 일정거리를 통해서 클러스터링을 하는 방법이라면,
DBSCAN 은 데이터의 밀집도(밀도)를 통해 군집을 나누는 방법이다.
DBSCAN의 장점은 비선형의 클러스터링이 가능하다는 것이다.

앱실론과 minspoint 수를 통해 클러스터링을 지정함 (파라미터)
-
앱실론 : 중심점으로부터 거리
-
minspoint : 앱실론 반경내에 샘플의 갯수
지정한 앱실론과 min 포인트수를 통해 밀도를 구하고 클러스터링 함
- 반경안에 들어오지 못한 points 는 noise point

코드
print(__doc__)
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
# #############################################################################
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
X = StandardScaler().fit_transform(X)
# #############################################################################
# Compute DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print('Estimated number of clusters: %d' % n_clusters_)
print('Estimated number of noise points: %d' % n_noise_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
# #############################################################################
# Plot result
import matplotlib.pyplot as plt
# Black removed and is used for noise instead.
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1]
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=14)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
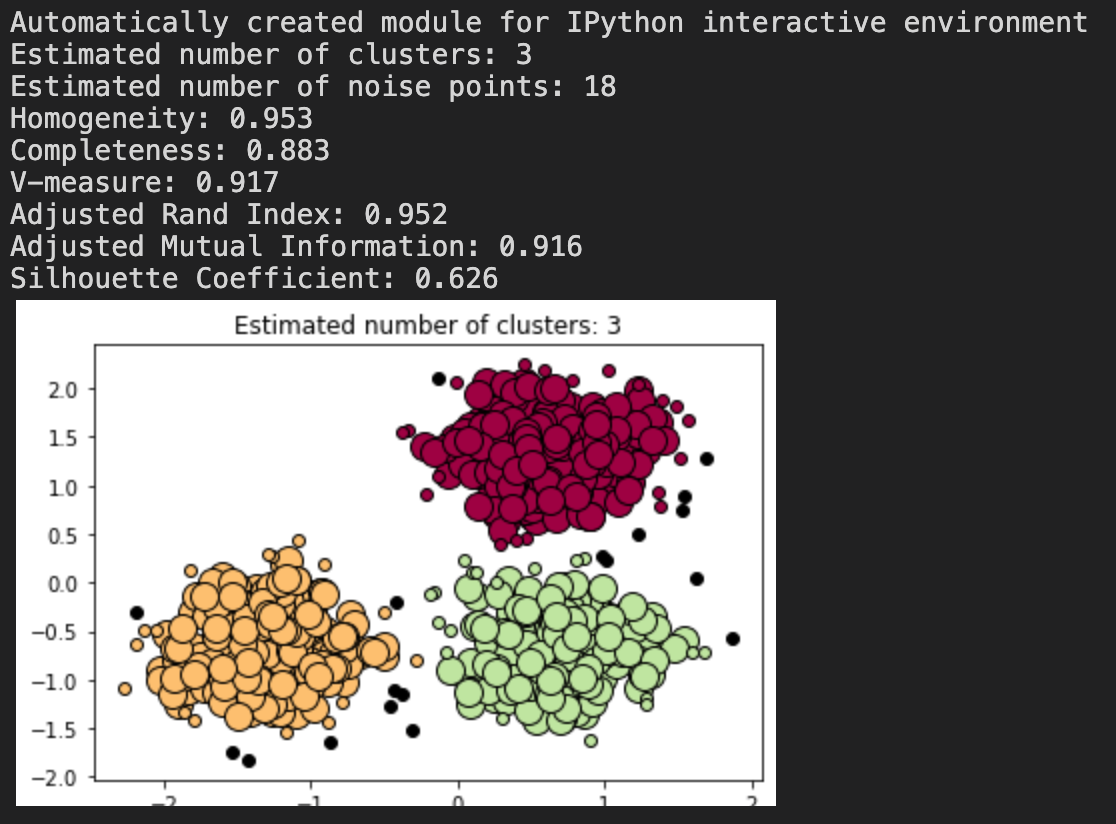
참고: scikit-learn.org/stable/auto_examples/cluster/plot_dbscan.html#sphx-glr-auto-examples-cluster-plot-dbscan-py
Demo of DBSCAN clustering algorithm — scikit-learn 0.24.0 documentation
Note Click here to download the full example code or to run this example in your browser via Binder Demo of DBSCAN clustering algorithm Finds core samples of high density and expands clusters from them. Out: Estimated number of clusters: 3 Estimated number
scikit-learn.org
DBSCAN - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search A density-based data clustering algorithm Density-based spatial clustering of applications with noise (DBSCAN) is a data clustering algorithm proposed by Martin Ester, Hans-Peter Krieg
en.wikipedia.org
'Machine Learning' 카테고리의 다른 글
| PCA (Principal Component Analysis) - 주성분 분석 (1) | 2021.01.13 |
|---|---|
| Batch normalization 적용으로 train set 데이터의 정규화 대체! (0) | 2021.01.08 |
| Anomaly Detection 종류(Point, Contextual, Collective) (0) | 2020.12.01 |
| tf.keras serving function을 이용한 feature transform 적용 방법 (0) | 2020.11.25 |
| Hierarchical temporal memory (HTM networks) (0) | 2020.08.11 |

