
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- tensorflow text
- Retry
- UDF
- TensorFlow
- 공분산
- session 유지
- API
- login crawling
- airflow subdag
- integrated gradient
- requests
- gather_nd
- grad-cam
- hadoop
- flask
- chatGPT
- subdag
- XAI
- GenericGBQException
- top_k
- correlation
- 상관관계
- GCP
- Airflow
- Counterfactual Explanations
- youtube data
- 유튜브 API
- API Gateway
- spark udf
- BigQuery
- Today
- Total
데이터과학 삼학년
[기초통계] 공분산과 상관계수 (covarience, correlation) 본문
공분산 : 각 두 확률변수간의 편차곱의 기대값
공분산의 경우, 비교하는 확률 변수간 스케일로 인해 실제 관계가 높더라고 수치자체는 낮게 나올 수 있다.
이러한 문제를 해결하기위해 공분산을 스케일링하는 개념이 상관계수라고 할 수 있다.
x와 y값이 얼마나 함께 같이 변동하는가
상관계수 : 공분산을 스케일링하는 개념
확률변수X가 있을때 우리가 흔히 이 분포를 나타낼때 쓰는것이
첫번째로 평균이고
두번째로 분산이다.
평균으로써 분포의 중간부분을 알아내고
분산으로써 분포가 얼마나 퍼져있는지 알아낸다.
더 알고싶으면 Skewness 혹은 직접 시각화 해보거나 방법이 있지만
우선 가장 쉽고 잘표현되는것이 평균과 분산이다.
그렇다면 확률변수가 2가지일때 이 확률분포들이 어떤모양으로 되어있는지를 알고싶을때
가장 먼저 X의 평균, 다음이 Y의 평균이다.
이렇게 되면 대충 분포가 어디에 주로 모여있는지 (m_x, m_y)가 나온다.
그다음으로 궁금한게 얼마나 퍼져있는지 인데 그것은 확률변수의 분산을 구하면 되지만
각 확률변수들이 어떻게 퍼져있는지를 나타내는 것이 공분산(Covariance)이다.,
두 확률변수 X와 Y가 어떤 모양으로 퍼져있는지
즉, X가 커지면 Y도 커지거나 혹은 작아지거나 아니면 별 상관 없거나 등을 나타내어 주는 것이다.
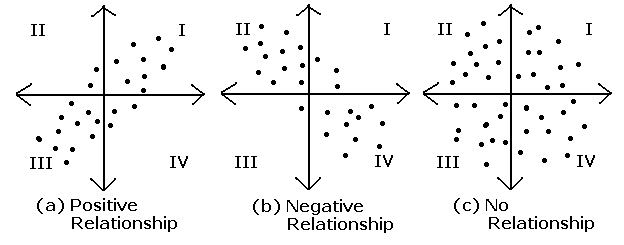
Cov(X, Y) > 0 X가 증가 할 때 Y도 증가한다.
Cov(X, Y) < 0 X가 증가 할 때 Y는 감소한다.
Cov(X, Y) = 0 공분산이 0이라면 두 변수간에는 아무런 선형관계가 없으며 두 변수는 서로 독립적인 관계에 있음을 알 수 있다.
그러나 두 변수가 독립적이라면 공분산은 0이 되지만, 공분산이 0이라고 해서 항상 독립적이라고 할 수 없다.
어떻게 하면 그것을 나타낼 수 있을까 고민한 결과
공분산은 아래와 같이 구하기로 하였다.
확률변수 X의 평균(기대값), Y의 평균을 각각
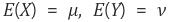
이라 했을 때, X,Y의 공분산은 아래와 같다.
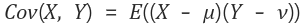
즉, 공분산은 X의 편차와 Y의 편차를 곱한것의 평균이라는 뜻이다.
좀더 간편하게 정리하면 아래와 같다.
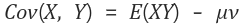
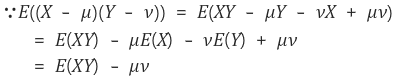
만약에 X와 Y가 독립이면
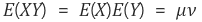
이므로 공분산은 0이 된다.
그런데 공분산에도 문제점이 하나 있다.
X와 Y의 단위의 크기에 영향을 받는다는 것이다.
즉 다시말해 100점만점인 두과목의 점수 공분산은 별로 상관성이 부족하지만 100점만점이기 때문에 큰 값이 나오고
10점짜리 두과목의 점수 공분산은 상관성이 아주 높을지만 10점만점이기 때문에 작은값이 나온다.
이것을 보완하기 위해 상관계수(Correlation)가 나타난다.
상관계수라는 개념이 왜 나왔는지 생각하다 보면 의외로 간단하다.
확률변수의 절대적 크기에 영향을 받지 않도록 단위화 시켰다고 생각하면 된다.
즉, 분산의 크기만큼 나누었다고 생각하면 된다.
상관계수의 정의는 아래와 같다.
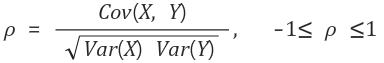
상관계수의 성질을 나열해 보자
1. 상관계수의 절대값은 1을 넘을 수 없다.
2. 확률변수 X, Y가 독립이라면 상관계수는 0이다.
3. X와 Y가 선형적 관계라면 상관계수는 1 혹은 -1이다.
양의 선형관계면 1, 음의 선형관계면 -1
출처: destrudo.tistory.com/15
공분산(Covariance)과 상관계수(Correlation)
확률변수X가 있을때 우리가 흔히 이 분포를 나타낼때 쓰는것이 첫번째로 평균이고 두번째로 분산이다. 평균으로써 분포의 중간부분을 알아내고 분산으로써 분포가 얼마나 퍼져있는지 알아낸다
destrudo.tistory.com
'Statistical Learning' 카테고리의 다른 글
| [기초통계] 모수, 비모수 (0) | 2020.12.23 |
|---|---|
| MLE vs OLS (0) | 2020.12.12 |
| [기초 통계] Q-Q Plot (feat. shapiro-test) (0) | 2020.11.28 |
| 큰 수의 법칙 (Law of Large Numbers (LoLN)), 중심극한의 정리 (Central Limit Theorem) (0) | 2020.11.17 |
| Outliers & leverage (0) | 2020.11.06 |


