
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- TensorFlow
- 공분산
- youtube data
- login crawling
- grad-cam
- API Gateway
- Retry
- Counterfactual Explanations
- airflow subdag
- GenericGBQException
- hadoop
- spark udf
- GCP
- tensorflow text
- 상관관계
- flask
- top_k
- subdag
- session 유지
- 유튜브 API
- XAI
- requests
- correlation
- API
- BigQuery
- gather_nd
- integrated gradient
- chatGPT
- Airflow
- UDF
- Today
- Total
목록Machine Learning (94)
데이터과학 삼학년
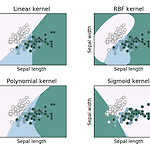 커널 함수(kernel function) 조건 및 종류
커널 함수(kernel function) 조건 및 종류
커널 함수(kernel function) - Support Vector Machine(SVM)과 같은 머신러닝 모델에서 사용되는 함수 - 커널 함수는 두 개의 입력 벡터를 받아 두 벡터 간의 유사도 또는 내적(inner product) 값을 계산하는 역할 - 유사도 또는 내적 값은 입력 데이터를 더 고차원 공간으로 매핑하거나 유사도를 측정하여 머신러닝 모델에서 판별 경계를 만들 때 사용 커널 함수 조건 : Mercer의 정리(Mercer's Theorem) - Mercer의 정리가 충족되면 커널 함수는 커널 트릭을 사용하여 고차원 특징 공간에서의 비선형 문제를 효과적으로 해결 가능 1. 대칭성(Symmetry) - 커널 함수 $K(x, y)$ 는 대칭성을 가져야 함 -> 즉, $K(x, y) = K(y,..
 TensorRT for Inference
TensorRT for Inference
TensorRT - Tensorflow의 latency를 낮춰 좋게 만들기위한 방법으로 TensorRT로 변환!!! - inference 최적화 및 latency를 최소화히기위한 플랫폼 - NVIDIA GPUs환경에서 작동 - TensorRT로 모든 주요 프레임웍에서 동작시킬수 있음 Tensorflow → TensorRT 변환 방법 - GPU환경에서 변환 가능 → TensorRT는 GPU에서 작동 가능함 - CPU에서 최적화하고 싶다면 OpenVino나 ONNX를 사용 from tensorflow.python.compiler.tensorrt import trt_convert as trt # Conversion Parameters conversion_params = trt.TrtConversionParam..
 Zero-Shot, One-Shot, Few-Shot learning
Zero-Shot, One-Shot, Few-Shot learning
인간은 새로운 물체를 볼때 적은 양의 샘플로도 구별할 수 있는데 기계(머신)은 수천장의 샘플이 필요함 제한된 양의 샘플로도 학습하여 만족할 만한 기계학습을 이루기 위한 개념에서 나온 Zero-Shot, One-Shot, Few-Shot learning 을 살펴보자~!!! >> meta learning -> learn to lerarn 학습하는 방법을 학습하는 것 >> 즉, 사람이 물체를 구별하는 방법을 학습하게 하는 시스템 -> 적은 양의 데이터로도 가능 Few shot learning vs Supervised learning - Supervised learning : Test image ( Query image ) 의 클래스가 Training set에 있음!! -> 학습에 강아지 사진을 주고 강아지를 ..
 SOTA (State-of-the-Art) 가장 최신의 성능 좋은 모델들...어떻게 확인?!
SOTA (State-of-the-Art) 가장 최신의 성능 좋은 모델들...어떻게 확인?!
SOTA (State-of-the-Art) 가장 최신의 성능 좋은 모델들...어떻게 확인할까?! 아래 사이트를 가면...확인 가능!!! 논문과 깃헙 주소까지 한번에 확인이 가능하다!!!!!!!!!! 데이터셋별 가장 좋은 성능의 퍼포먼스를 낸 모델까지 정리되어 있다! https://paperswithcode.com/sota Papers with Code - The latest in Machine Learning Papers With Code highlights trending Machine Learning research and the code to implement it. paperswithcode.com
 SCIKIT_LLM (sklearn + llm), large language model을 쉽게 쓰자!!!
SCIKIT_LLM (sklearn + llm), large language model을 쉽게 쓰자!!!
SCIKIT_LLM open-AI의 llm 모델을 사용하기 편리하게 나온 툴 sklearn + llm(large language model) 익숙한 sklearn 학습, 예측 방식으로 llm의 모델들을 편리하게 활용 가능 llm의 모델들을 쓰는 장점 → 텍스트를 벡터화하고 전처리하는 과정들이 생략될 수 있다.!!! 아래 예제를 통해 확인!!! Configuring OpenAI API Key Scikit-LLM estimators 는 OpenAI API key 가 필요 from skllm.config import SKLLMConfig SKLLMConfig.set_openai_key("") SKLLMConfig.set_openai_org("") free 라이센스의 경우, 1분당 3번의 요청으로 요청 제한이 ..
CatBoost는 카테고리 변수를 별도 처리하지 않아도 지정만 해주면(indices 등) 자동으로 encoding처리를 해준다. 그렇다면 CatBoost에서 사용하는 카테고리 변수를 인코딩 방법은 무엇일까?! 주요 용어 * TargetSum: Sum of the target value for that particular categorical feature in the whole dataset. - encoding 변환시키고자 하는 카테고리 변수에 할당된 타겟값의 합 * Prior: (sum of target values in the whole dataset)/ ( total number of observations (i.e. rows) in the dataset) - 전체 데이터셋의 타겟(y)값 총 합 ..
Auto-sklearn - 모델 선택과 하이퍼파라미터 조정을 포함한 과정은 많은 시간과 노력을 요구됨 - 이러한 어려움을 극복하기 위해 Auto-sklearn라는 자동화된 머신러닝 도구가 Auto-sklearn - scikit-learn 라이브러리를 기반으로한 자동화 도구로, 최적의 모델을 찾고 최상의 성능을 달성하는 머신러닝 프로세스를 간소화 Auto-sklearn의 작동 원리 - Auto-sklearn은 베이지안 최적화와 메타 모델링을 통해 머신러닝 모델의 선택과 하이퍼파라미터 조정을 자동화 - 베이지안 최적화는 여러 알고리즘과 하이퍼파라미터 조합을 시도하고, 모델의 성능을 평가하여 최적의 조합을 찾음 - 메타 모델링은 이전 실험 결과를 사용하여 모델 선택 및 하이퍼파라미터 조정을 가속화 Auto-s..
히스토그램 기반 그래디언트 부스팅 트리(Histogram Gradient Boosting Tree) - 히스토그램 기반 그래디언트 부스팅 트리는 앙상블 학습 방법 중 하나로, 여러 개의 결정 트리를 조합하여 예측 모델을 구축하는 알고리즘 - 트리 기반의 모델인 그래디언트 부스팅 트리(Gradient Boosting Tree)를 기반으로 함 - 특히 데이터를 히스토그램으로 변환하여 학습 및 예측에 활용하는 점이 특징 동작 원리 1. 데이터의 특성을 이해하기 위해 먼저 히스토그램으로 변환 -> 이를 위해 입력 데이터를 여러 개의 구간(bin)으로 나누고, 각 구간에 속하는 데이터 포인트의 개수를 기록 2. 초기에는 단 하나의 트리로 시작하며, 이 트리는 모든 데이터를 하나의 잎(leaf)에 할당 3. 그 다..