
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Counterfactual Explanations
- 공분산
- UDF
- Retry
- login crawling
- chatGPT
- GCP
- API Gateway
- spark udf
- tensorflow text
- session 유지
- BigQuery
- youtube data
- API
- Airflow
- top_k
- XAI
- requests
- integrated gradient
- flask
- GenericGBQException
- 유튜브 API
- hadoop
- grad-cam
- correlation
- airflow subdag
- gather_nd
- TensorFlow
- subdag
- 상관관계
- Today
- Total
데이터과학 삼학년
GCP Dataflow를 이용한 텍스트 전처리 (feat. universal sentence encoder) 본문
Dataflow를 이용한 텍스트 전처리 (feat. universal sentence encoder)
-
Tensoflow 1.13 버전에서 실행 (transfer learning 버전은 tf 1)
-
TF 2.x 버전의 transfer learning을 사용할 경우 아래링크와 같은 문제 발생 [https://github.com/tensorflow/transform/issues/160]
전처리 과정
-
형태소 분석 : raw text data를 형태소단위 token 및 stopword 제거
-
정제된 raw data 는 GCS 및 Bigquery table 로드
-
Transfer learning : 정제된 raw data를 universal sentence encoder multilingual을 이용하여 벡터화 (512 dimensional)
-
Extract : 벡터화 된 데이터를 GCS 및 Bigquery table 로드
예시)
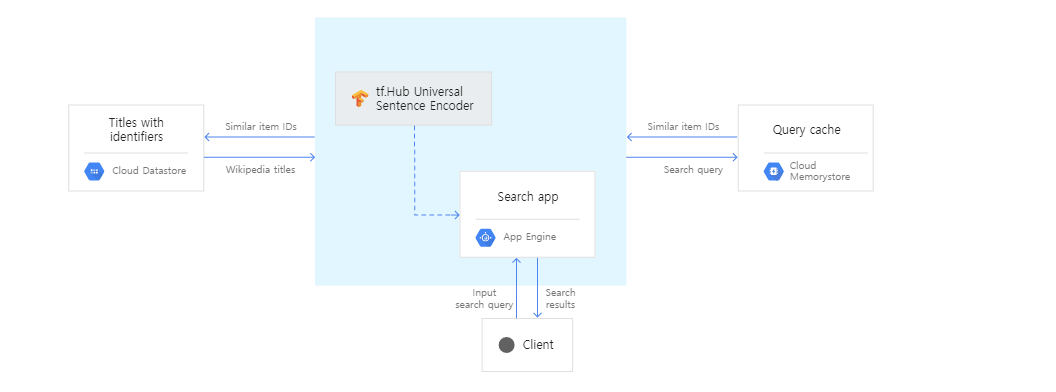
전처리 세부 과정
-
형태소 분석
-
stopword 제거
-
정제된 한글, 영어 데이터는 GCS, BQ table로 내보냄
-
-
한글 : mecab, 영어 : nltk 사용
-
그 외 언어 형태소 분석 미적용
-
Transfer learning
-
universal sentence encoder multilingual (cnn) 모델을 이용하여 벡터화
-
tensorflow transform 을 이용하여 병렬 처리
-
Extract
-
GCS
-
BQ table로 적용
Dataflow Pipeline
-
apache beam을 기반으로 GCP dataflow 가 만들어지고 병렬처리로 돌아감 (ETL 과정, Extract, Transform, Load)
-
runner 설정
-
DirectRunner : 로컬에서 실행 // DataflowRunner : Dataflow에서 실행
-
-
python 코드로 beam.Pipeline 문법 간략 소개
-
<이어서 실행시킬 객체> | ‘<stage명>’ >> [실행시킬 함수]
-
간략한 예제 코드
-
pipeline.py
-
import os
from time import time
import apache_beam as beam
from apache_beam.io import WriteToText
from apache_beam.options.pipeline_options import PipelineOptions
import tensorflow as tf
import tensorflow_text
import tensorflow_transform as tft
import tensorflow_transform.beam as tft_beam
from tensorflow_transform.beam.tft_beam_io import transform_fn_io
#====== options =========
pipeline_options = PipelineOptions(None)
DEST_DIR = "gs://data/"
job_name = 'dataflow-use'
options = {
'runner':'DataflowRunner',
'num_workers' : 10,
'machine_type' : 'n1-highmem-16',
'staging_location': DEST_DIR + 'staging',
'temp_location': DEST_DIR + 'tmp',
'job_name': job_name,
'project': 'project_id',
'region' : 'us-central1',
'teardown_policy': 'TEARDOWN_ALWAYS',
'no_save_main_session': True ,
'save_main_session': False,
'service_account_email' : 'user@project-id.iam.gserviceaccount.com',
'setup_file' : './setup.py'
}
opts = beam.pipeline.PipelineOptions(flags=[], **options)
#====== preprocess_for_embedding =========
encoder = None
def preprocess_fn(input_features):
import tensorflow_transform as tft
embedding = tft.apply_function(embed_text, input_features['data']) # apply_function은 더 이상 필요(과거 TensorFlow 그래프를 검사하는 tf.Transform 기능의 제한으로 인해 필요)
# embedding = embed_text(input_features['data'])
output_features = {
'user': input_features['user'],
'logkey': input_features['logkey'],
'data': input_features['data'],
'embedding': embedding
}
return output_features
def embed_text(text):
import tensorflow_hub as hub
import tensorflow_text
global encoder
use_url = "https://tfhub.dev/google/universal-sentence-encoder-multilingual/1" ## hub.Module v1으로 해야 실행됨 : session을 쓸 수 있도록 graph형태로 output이 나와야함
if encoder is None:
encoder = hub.Module(use_url)
outputs = encoder(text)
return outputs
#====== metadata 구성 =========
def get_metadata():
from tensorflow_transform.tf_metadata import dataset_schema
from tensorflow_transform.tf_metadata import dataset_metadata
metadata = dataset_metadata.DatasetMetadata(
dataset_schema.from_feature_spec({
'pid': tf.io.FixedLenFeature([], tf.string),
'logkey': tf.io.FixedLenFeature([], tf.string),
'data': tf.io.FixedLenFeature([], tf.string),
}))
return metadata
sql="""
SELECT * FROM `project.dataset.data_preprocess` LIMIT 1000
"""
#====== load Bigquey =======
def to_bq_row(entry):
# might not need to round...
entry['embedding'] = [round(float(e), 3) for e in entry['embedding']]
return entry
def get_bigquery_schema():
"""
Returns a bigquery schema.
"""
from apache_beam.io.gcp.internal.clients import bigquery
table_schema = bigquery.TableSchema()
columns = (('user', 'string', 'nullable'),
('logkey', 'string', 'nullable'),
('data', 'string', 'nullable'),
('embedding', 'float', 'repeated'))
for column in columns:
column_schema = bigquery.TableFieldSchema()
column_schema.name = column[0]
column_schema.type = column[1]
column_schema.mode = column[2]
table_schema.fields.append(column_schema)
return table_schema
#====== pipeline =========
## tfx 버전
transform_temp_dir = DEST_DIR + '/transform_temp_dir'
with tft_beam.Context(transform_temp_dir):
pipeline = beam.Pipeline('DataflowRunner', options=opts)
raw_data =(
pipeline
| 'Read from BigQuery' >> beam.io.Read(beam.io.BigQuerySource(project='nm-dataintelligence', query=sql, use_standard_sql=True))
)
dataset = (raw_data, get_metadata())
result1 = (
raw_data
| 'Write raw data to gcs' >> WriteToText(DEST_DIR + job_name + '/raw_output'+ '/output',file_name_suffix='.txt')
)
# embeddings_dataset, _ = (
# dataset
# | 'Embedding data' >> tft_beam.AnalyzeAndTransformDataset(preprocess_fn) ### input 이 tensor로 들어가야함(기존 use-multilingual은 tensor가 아닌 text를 input으로 받게 되어 있음
# )
transform_fn = (
dataset
| 'Analyse dataset' >> tft_beam.AnalyzeDataset(preprocess_fn)
)
transformed_data_with_meta = (
(dataset, transform_fn)
| 'Transform dataset' >> tft_beam.TransformDataset()
)
transformed_data, transformed_metadata = transformed_data_with_meta
transform_fn | 'Export Transform Fn' >> transform_fn_io.WriteTransformFn(
DEST_DIR + job_name + '/transform_export_dir')
result2 = (
transformed_data
| 'Convert to Insertable data' >> beam.Map(to_bq_row)
| 'Write to BigQuery table' >> beam.io.WriteToBigQuery(
project='project_id',
dataset='dataset',
table='dataflow_preprocess',
schema=get_bigquery_schema(),
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE)
)
### pipeline 실행
result = pipeline.run()
result.wait_until_finish()-
setup.py
-
universal sentence encoder multilingual 모델을 사용할때 반드시 sentencepiece 와 tf-sentencepiece 모두 설치해야함
-
import setuptools
REQUIRED_PACKAGES = [
'apache-beam[gcp]==2.22.0', ##dataflow Python worker version 2.22.0. 무조건 이렇게 설치해야함
'numpy==1.18.5',
'tensorflow==1.13.0',
'tensorflow-text==1.15.0',
'tensorflow-hub==0.7.0',
'tensorflow-transform==0.15.0',
'tf-sentencepiece==0.1.90',
'sentencepiece==0.1.91'
]
setuptools.setup(
name='use_pipeline',
version='0.0.1',
author='bdh',
author_email='user@doamin.com',
install_requires=REQUIRED_PACKAGES,
packages=setuptools.find_packages()
)
-
결과
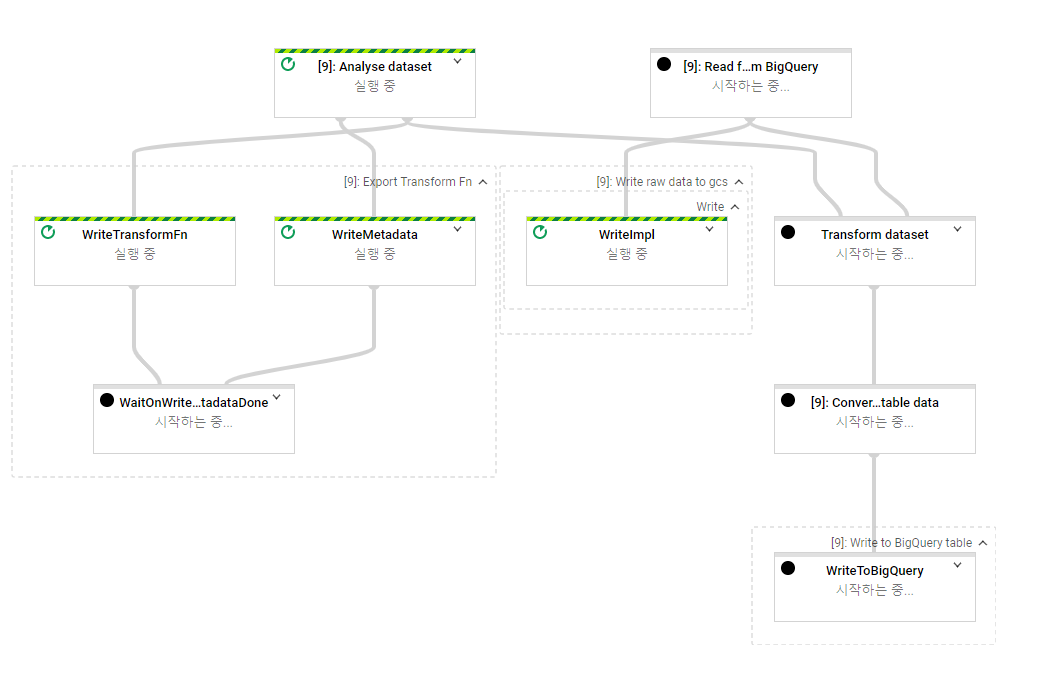
이슈
-
tf 2.x 대 구성된 universal sentence encoder가 tfx에서 실행안됨 (graph 관련 error)
-
동일한 문제를 갖고 있는 개발자 대다수
-
tensorflow transform git에 이슈 제기됨
https://github.com/tensorflow/transform/issues/160
-
tf 1.x 대 구성한 universal sentence encoder 는 잘 실행됨 (https://tfhub.dev/google/universal-sentence-encoder/2)
-
그러나, tf1.x 대 구성된 use-multilingual 은 작동 안함
-
sentencepiece 관련 에러
-
Graph ops missing from the python registry ({'SentencepieceEncodeSparse'}) are also absent from the c++ registry.
-
sentencepiece 라이브 관련 에러로 sentence library 구성해줌 (맞는 버전이 따로 있음...)
-
sentencepiece 는 unsupervised 모듈로 soynlp와 비슷하게 corpus를 학습해 bqe 알고리즘에 의해 문장 분리
해결
-
tf 2 버전의 transfer learning의 버그로 tf1 버전의 transfer learning으로 dataflow 구성
-
use / use-multilingual 모델 두개 정상작동 확인 → bigquery table 적재 완료
-
소요시간 Direct Runner
-
CPU times: user 2min 5s, sys: 1min 30s, total: 3min 36s
-
Wall time: 4min 54s
-
dataflow 환경설정 매우 중요
-
'apache-beam[gcp]==2.22.0', ##dataflow Python worker version 2.22.0. 무조건 이렇게 설치해야함
-
버전 명시안하면 2.23.0이 설치되어 error 발생 (python worker 미지원)
-
universal sentence encoder multilingual 모델을 사용할때 반드시 sentencepiece 와 tf-sentencepiece 모두 설치해야함
파이프라인 spec 관련 설정 참고
파이프라인 실행 매개변수 지정 | Cloud Dataflow | Google Cloud
Apache Beam 프로그램이 파이프라인을 구성하면 사용자는 파이프라인을 실행해야 합니다. 파이프라인 실행은 Apache Beam 프로그램 실행과는 별개입니다. Apache Beam 프로그램에서 파이프라인이 생성되
cloud.google.com
'GCP' 카테고리의 다른 글
| Cloud Scheduler로 Compute 인스턴스 예약 (feat. cloud function, cloud pub/sub) (0) | 2020.10.29 |
|---|---|
| [Bigquery client] BQ client를 이용하여 dataframe 의 array 데이터 빅쿼리에 올리기 (0) | 2020.08.28 |
| Bigquery ML (0) | 2020.07.21 |
| Cloud Run VS Cloud Functions (0) | 2020.06.25 |
| pandas - GCP GCS 로 읽기, 쓰기 (0) | 2020.06.24 |



