
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- chatGPT
- tensorflow text
- GenericGBQException
- hadoop
- XAI
- correlation
- youtube data
- Counterfactual Explanations
- 공분산
- API Gateway
- API
- login crawling
- Airflow
- top_k
- TensorFlow
- UDF
- airflow subdag
- gather_nd
- GCP
- BigQuery
- subdag
- Retry
- integrated gradient
- session 유지
- 상관관계
- 유튜브 API
- spark udf
- grad-cam
- flask
- requests
- Today
- Total
데이터과학 삼학년
Operationalizing the Model 본문
Operationalizing the Model
- data pipeline → dataflow에서 확인할 수 있음
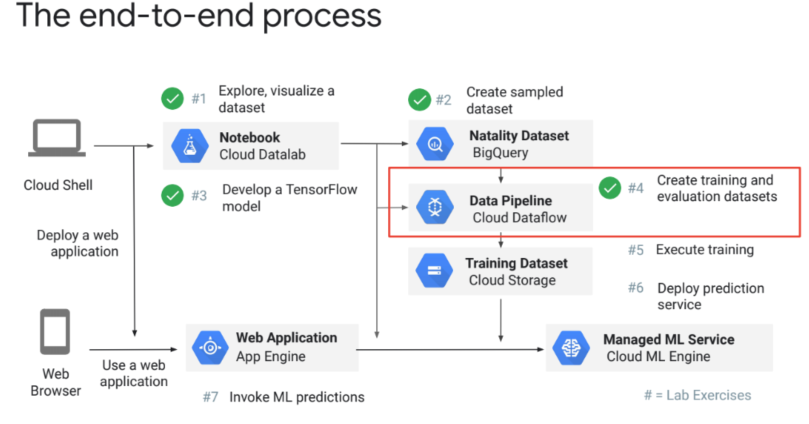
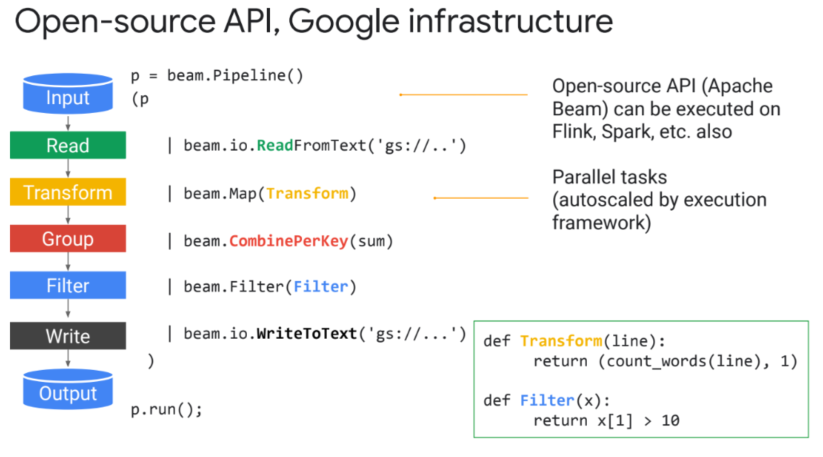
- 아파치 빔을 이용해서 preprocess pipeline을 구성
- 큰데이터를 sharding하여 처리하기 위해 ai-platform을 사용함
> 기본 파일 setting

- 하이퍼파라미터 튜닝을 위해 task.py에 해당하는 argument를 잘 작성해야함

- 로컬모드로 실험적으로 돌려보고 ai-platform에 올려 돌리기!
> 조금 형식이 다르긴 함 → job submit 분산처리용(cloud)

- hidden layer에 있는 뉴런들이 얼마나 0값을 가지고 있는지도 텐서보드에서 확인할 수 있음
> 세로축이 죽은 뉴런들의 비율 → 위로 올라가면 그 layer에 해당하는 뉴런들이 다죽은 것
> 많은 뉴런들이 죽는다는 것은 좋은 것이야!! → 다만 모두 죽으면 안돼

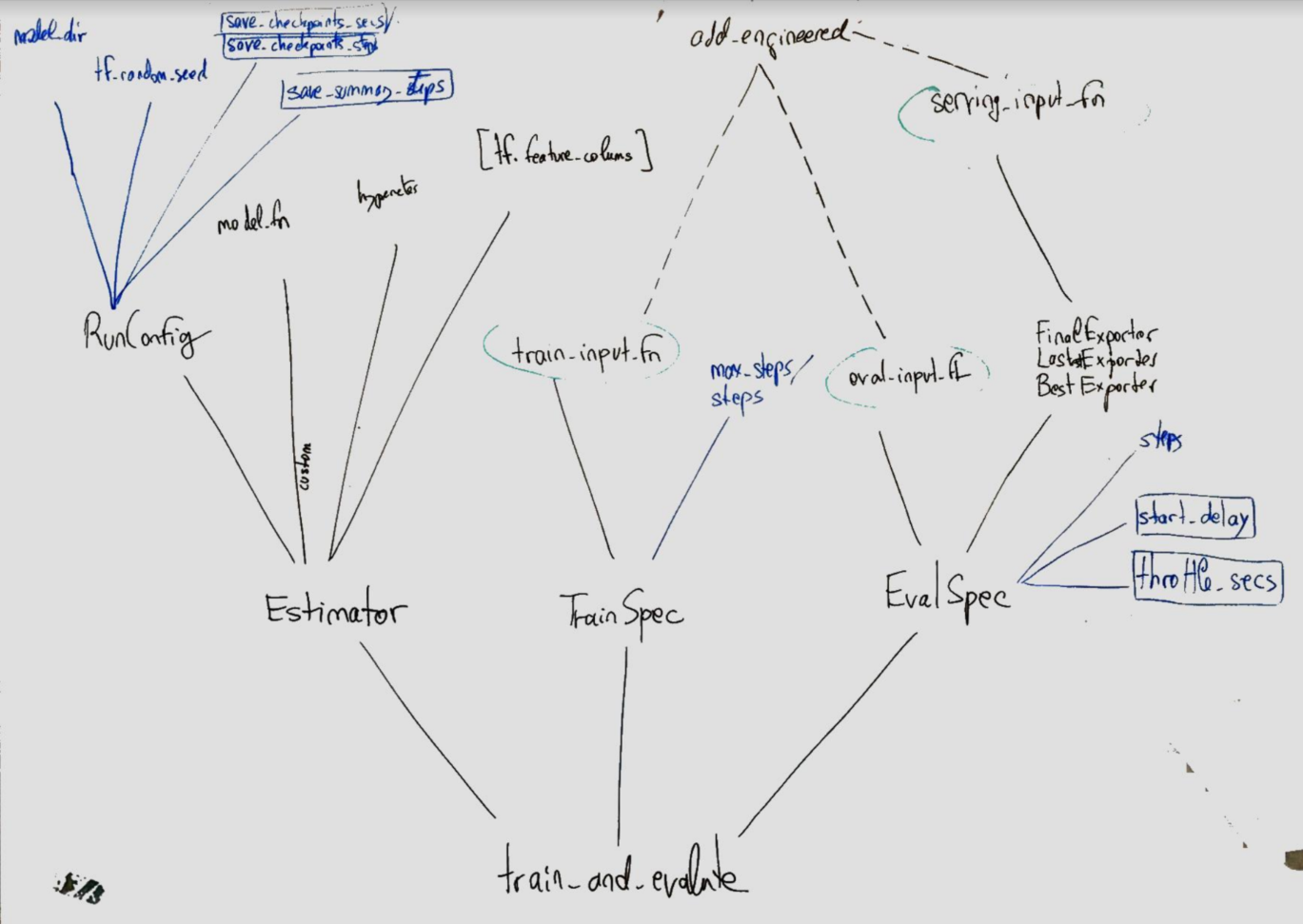
- TRAIN_AND_EVALUATE 로직
- deploy한 모델을 이용하여 서비스 제공 -
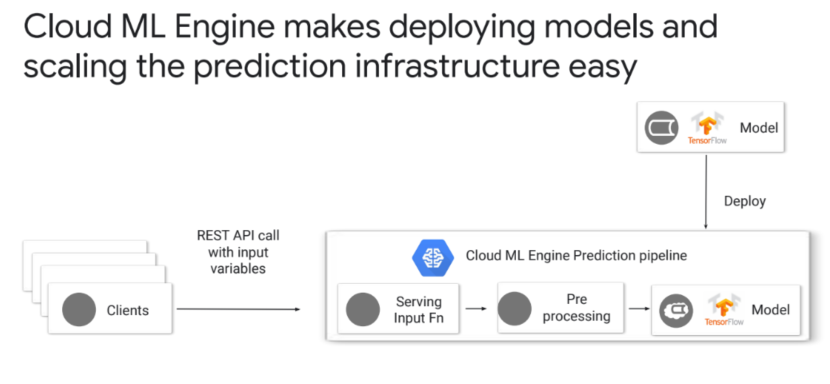
- api가 받게 되는 data feature 형태를 정해줌

- model의 이름을 정해주고 → 모델버전을 생성해주는 것
> origin이라는 곳에 모델이 저장된 위치를 알려줘야함
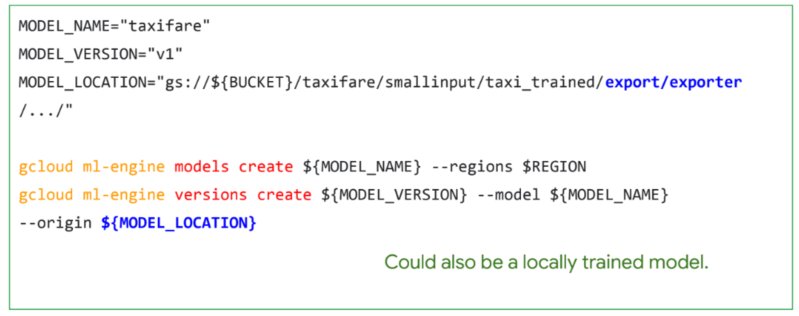
- 웹에서의 요청(데이터 보내주기)을 GCP로 POST 날리는 방식으로 APP 구현 가능

- WEB appication을 통해서 app engine을 ai-platform에 연결하여 사용~
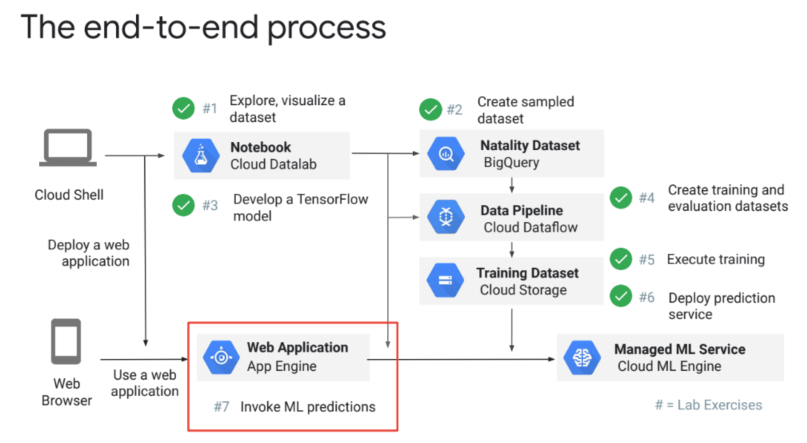

- GCP에 model 버전을 등록한 후 AppEngine을 이용하여 서비스 구현함
https://qwiklabs-gcp-ml-196710c70792.appspot.com/form

'Machine Learning' 카테고리의 다른 글
| Tensorflow 2.0 (0) | 2020.02.03 |
|---|---|
| Tensoflow train_and_evlauate 구성도 (0) | 2020.02.03 |
| ML Ops and Kubeflow Pipelines (0) | 2020.02.03 |
| Explore and Creating the Dataset (0) | 2020.02.03 |
| Preprocessing and feature creations (with Cloud Dataprep) (0) | 2020.02.03 |


