
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 상관관계
- youtube data
- 유튜브 API
- session 유지
- flask
- Retry
- GenericGBQException
- UDF
- correlation
- gather_nd
- login crawling
- tensorflow text
- chatGPT
- Counterfactual Explanations
- TensorFlow
- subdag
- spark udf
- BigQuery
- top_k
- Airflow
- requests
- airflow subdag
- 공분산
- XAI
- API Gateway
- GCP
- grad-cam
- integrated gradient
- hadoop
- API
- Today
- Total
데이터과학 삼학년
All about Feature Scaling 본문
All about Feature Scaling
Feature scaling 필요성
- feature scaling은 머신러닝알고리즘에서 데이터간 거리를 계산하는데 필요함
- scaling을 하지 않으면, 더 넓은 범위의 값을 가지는 feature가 거리를 계산하는데 주된 기준이 될 것임
- 머신러닝 모델을 학습시키는데 있어서 빠른 수렴(faster convergence)를 하는데 큰 도움이 되는 것이 scaling임

- feature scaling 이해
Feature scaling이 필수인 알고리즘
- KNN
- K-Means
- PCA
- Gradient Descent
Feature scaling이 필수가 아닌 알고리즘
- rule에 의존하는 알고리즘
- CART
- Random Forest
- Gradient Boosted Decision Tree
- LDA(Linear Discriminant Analysis), Naive Bayes는 알고리즘 자체에 feature간 weight를 주는 것이 들어가 있어 별도로 하지 않아도 됨
Feature scaling의 종류
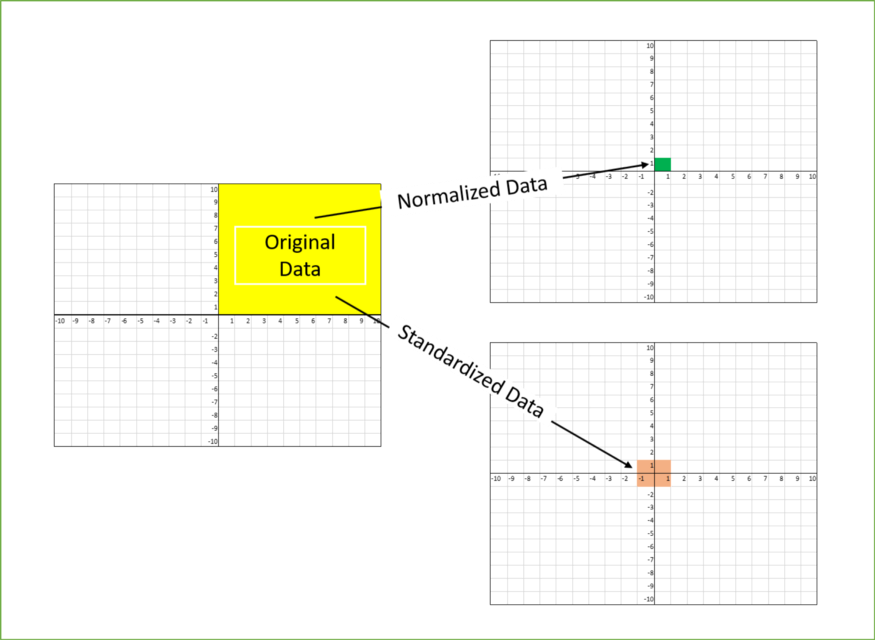
1) Min Max Scaler
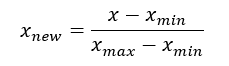
2) Standard Scaler
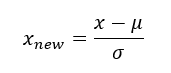
3) Max Abs Scaler
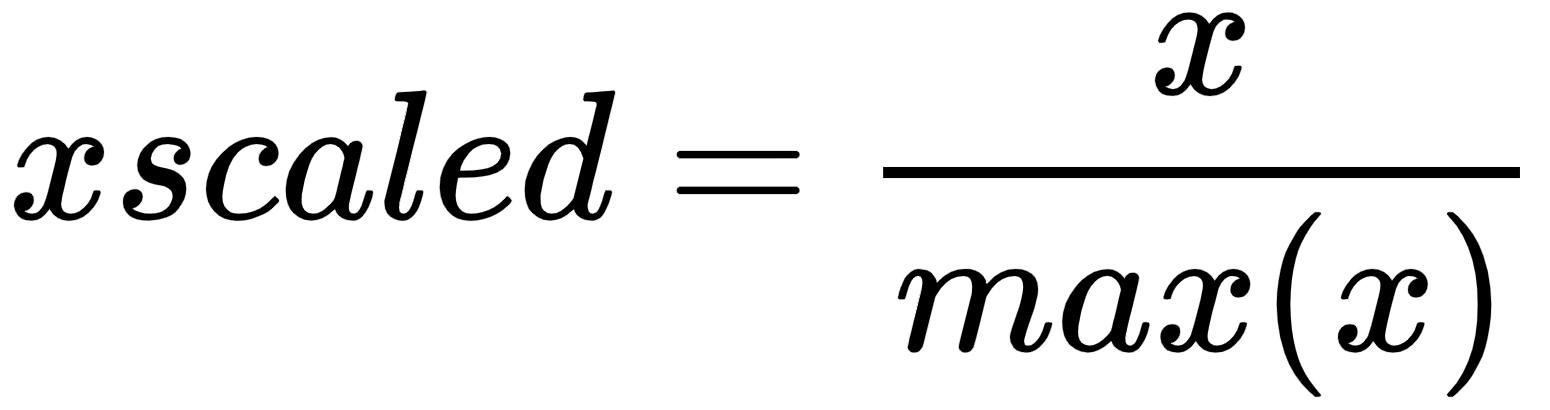
4) Robust Scaler
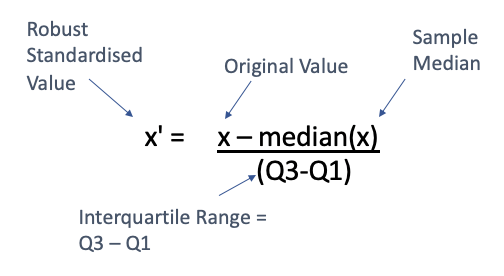
5) Mean Normalization

6) Quantile Transformer Scaler
- quantile transform은 변수의 확률 변수를 다른 확률분포로 매핑시키는 것을 의미함
- 예를 들면 feature1의 데이터 분포를 분위수를 이용하여 가우시안(정규)분포의 분위수에 매핑하는 것을 의미함
- 이렇게 scaler를 진행할 경우, 변경하고자하는 분포에 정확하게 scaling할 수 있다는 장점은 있으나, 데이터 자체의 고유 분포가 깨질 수 있는 약점도 가지고 있는 것으로 보임
6) Power Transformer Scaler
- power를 이용한 transform 방법으로 box-cox와 거의 유사하다고 생각하면 됨
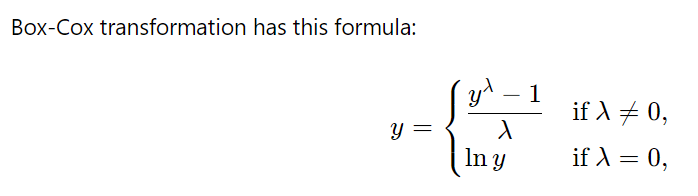

7) Unit Vector Scaler

참조
https://towardsdatascience.com/all-about-feature-scaling-bcc0ad75cb35
https://www.kaggle.com/code/aimack/complete-guide-to-feature-scaling/notebook
'Feature Engineering' 카테고리의 다른 글
| Feature Selection :: Recursive Feature Elimination (RFE) (0) | 2023.09.21 |
|---|---|
| [Labeling] Snorkel 소개 (1) | 2020.11.20 |
| Ch.9 Back to the Feature: Building an Academic Paper Recommender (0) | 2020.06.03 |
| Ch.7 Nonlinear Featurization viaK-Means Model Stacking (0) | 2020.05.21 |
| Ch.6 Dimensionality Reduction: Squashing the Data Pancake with PCA (0) | 2020.05.06 |
