
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- API
- top_k
- spark udf
- GenericGBQException
- 공분산
- requests
- tensorflow text
- BigQuery
- API Gateway
- Retry
- Airflow
- GCP
- gather_nd
- session 유지
- XAI
- 상관관계
- login crawling
- grad-cam
- TensorFlow
- hadoop
- airflow subdag
- subdag
- chatGPT
- flask
- youtube data
- correlation
- Counterfactual Explanations
- 유튜브 API
- integrated gradient
- UDF
- Today
- Total
데이터과학 삼학년
[TF 2.x] model layer에 text vectorization 단계를 넣기 본문
[TF 2.x] model layer에 text vectorization 단계를 넣기
Dan-k 2020. 7. 15. 15:06TF.2.2.0 버전 이상부터 experimental로 model의 layer에 text vectorization을 넣어주는 것이 나왔다.
이말인 즉슨,
기존에 model에 text를 태우기 위해서는 model에 들어갈 input을 vector화시키는 작업을 진행한 후 태웠다.
예를 들면 "나는 학교에 간다" 라는 문장을 [23,10,5,0,0,0,0,0] 으로 vector화 하여 태웠던 것을 말한다.
그러나,
tf.keras.layers.experimental.preprocessing.TextVectorization
이것이 나옴으로써 모델에 데이터를 넣기 위해 전처리를 할 필요가...사라졌다...
파이프라인을 비교하면 아래와 같다.
기존(일반적)
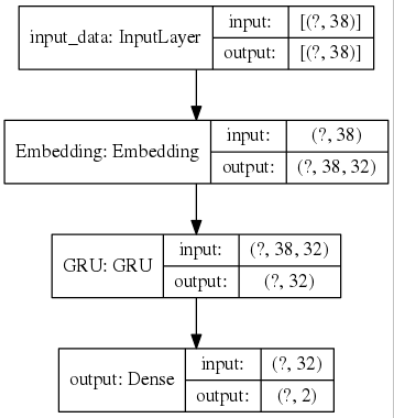
개선
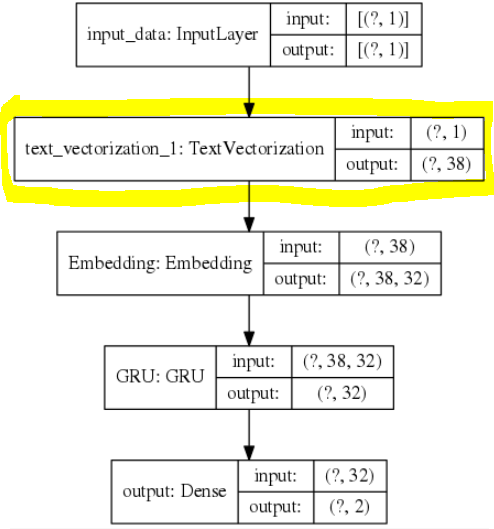
모델의 graph를 보면 알 수 있듯 모델 자체에 text vectorization이 있어 따로 전처리를 할 필요도 없거니와,
모델을 저장하면, 예측할 때 어떤 데이터가 오든 간에 모델을 학습시켰던 데이터에 기반한 tokenizer와 vocab을 따로 불러오지 않고 예측할 수 있다.
import os
import urllib
import pandas as pd
import tensorflow as tf
from tensorflow.keras import Input, Model
from tensorflow.keras import optimizers
from tensorflow.keras.layers import (
Dense,
Lambda,
Embedding,
GRU
)
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
print(tf.__version__)
from sklearn.model_selection import train_test_split
## 모델 만들기 : RNN
def build_rnn_model(vocab_size, embed_dim, max_len, units, n_classes):
input_text_raw_data = Input(shape=(1,), name="input_data", dtype=tf.string)
input_data = TextVectorization(max_tokens=vocab_size, output_mode='int', output_sequence_length=max_len)(input_text_raw_data)
embed = Embedding(vocab_size + 1, embed_dim, input_length=max_len, mask_zero=True, dtype=tf.float32, name='Embedding')(input_data)
gru = GRU(32, activation=tf.nn.relu, name="GRU")(embed)
output = Dense(2, activation=tf.nn.softmax, name="output")(gru)
model = Model(inputs=input_text_data, outputs=output)
return model
rnn_model = build_rnn_model(VOCAB_SIZE, 32, MAX_LEN, 32, 2)
rnn_model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
rnn_model.fit(X_train,y_train)
MODEL_EXPORT_PATH = './textvectors_rnn_model/'
tf.saved_model.save(rnn_model, MODEL_EXPORT_PATH)
이렇게 모델 내부에 textvecotrization layer을 넣고 학습시킨 후 저장한다.
이때 주의할 점은 input을 받을때 string 문서 전체를 shape 1로 받아서 처리하는 것이다.
이후 모델을 다시 불러와 예측 데이터의 정보도 함께 표출시키기 위해 serving_signature을 정의후 다시 모델을 저장한다.
주의할 점 모델 로드할때 custom_objects 를 쓰지 않으면 textvectorizaion layer의 vocab을 못가지고 와 벡터화된 모든 값이 oov(out of vocabulary)인 1로 처리되니 꼭 확인바람
custom_object를 지정하지 않으면 벡터화는 아래처럼 됨 -->
모델 저장 전 [4,2,3,1,2,0,0,0,0,0]
모델 로드 후 [1,1,1,1,1,0,0,0,0,0]
## load model
loaded_model = tf.keras.models.load_model(MODEL_EXPORT_PATH, custom_objects={"TextVectorization":TextVectorization})
@tf.function(input_signature=[tf.TensorSpec([None], dtype=tf.string), tf.TensorSpec([None, 1], dtype=tf.string)])
def keyed_prediction(key, data):
pred = loaded_model(data, training=False)
return {
'output': pred,
'key': key
}
KEYED_EXPORT_PATH = './keyed_textvectors_rnn_model/'
loaded_model.save(KEYED_EXPORT_PATH, signatures={'serving_default': keyed_prediction})마지막으로 예측 데이터와 예측 결과를 보면
with open("keyed_txt_input.json", "w") as file:
print('{"data": ["간만에 웃는다! 아하하하!!!"], "key": "id_1234"}', file=file)
!gcloud ai-platform predict --model experimenta_keyed_model --json-instances keyed_txt_input.json --version v2 --signature-name serving_default
====================
KEY OUTPUT
id_1234 [0.5073323845863342, 0.492667555809021]위처럼 text 자체를 모델에 넣었음에도 결과가 모델에 잘타고 나오게 된다.
tf.keras.layers.experimental.preprocessing.TextVectorization
에 대해 더 알아보자.
tf.keras.layers.experimental.preprocessing.TextVectorization(
max_tokens=None, standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE, ngrams=None, output_mode=INT,
output_sequence_length=None, pad_to_max_tokens=True, **kwargs
)Attributes
| max_tokens | The maximum size of the vocabulary for this layer. If None, there is no cap on the size of the vocabulary. vocab의 사이즈라고 생각하면 됨 |
| standardize | Optional specification for standardization to apply to the input text. Values can be None (no standardization), 'lower_and_strip_punctuation' (lowercase and remove punctuation) or a Callable. Default is 'lower_and_strip_punctuation'. |
| split | Optional specification for splitting the input text. Values can be None (no splitting), 'whitespace' (split on ASCII whitespace), or a Callable. The default is 'whitespace'. tokenizer의 split으로 기본 값은 ' ' 띄어쓰기로 되어있음 |
| ngrams | Optional specification for ngrams to create from the possibly-split input text. Values can be None, an integer or tuple of integers; passing an integer will create ngrams up to that integer, and passing a tuple of integers will create ngrams for the specified values in the tuple. Passing None means that no ngrams will be created. n-gram vectorizer 의 n을 의미함 |
| output_mode | Optional specification for the output of the layer. Values can be "int", "binary", "count" or "tf-idf", configuring the layer as follows: "int": Outputs integer indices, one integer index per split string token. "binary": Outputs a single int array per batch, of either vocab_size or max_tokens size, containing 1s in all elements where the token mapped to that index exists at least once in the batch item. "count": As "binary", but the int array contains a count of the number of times the token at that index appeared in the batch item. "tf-idf": As "binary", but the TF-IDF algorithm is applied to find the value in each token slot. output_mode로 vector 방법을 고를 수 있음, 우리가 익히 아는 tf-idf 도 있으며, int의 경우 단순한 seqVec 이라고 생각하면 됨 |
| output_sequence_length | Only valid in INT mode. If set, the output will have its time dimension padded or truncated to exactly output_sequence_length values, resulting in a tensor of shape [batch_size, output_sequence_length] regardless of how many tokens resulted from the splitting step. Defaults to None. output의 길이를 의미함 (max_len) |
| pad_to_max_tokens | Only valid in "binary", "count", and "tf-idf" modes. If True, the output will have its feature axis padded to max_tokens even if the number of unique tokens in the vocabulary is less than max_tokens, resulting in a tensor of shape [batch_size, max_tokens] regardless of vocabulary size. Defaults to True. max_len의 길이에 맞춰 padding하는 것을 말함(기본적으로 padding이 적용 되어 있음) |
tf.keras.layers.experimental.preprocessing.TextVectorization
See Stable See Nightly Text vectorization layer. tf.keras.layers.experimental.preprocessing.TextVectorization( max_tokens=None, standardize=LOWER_AND_STRIP_PUNCTUATION, split=SPLIT_ON_WHITESPACE, ngrams=None, output_mode=INT, output_sequence_length=None, p
www.tensorflow.org