
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- correlation
- 상관관계
- UDF
- GenericGBQException
- chatGPT
- integrated gradient
- API Gateway
- login crawling
- airflow subdag
- flask
- gather_nd
- TensorFlow
- requests
- spark udf
- XAI
- grad-cam
- Retry
- youtube data
- Counterfactual Explanations
- Airflow
- API
- tensorflow text
- session 유지
- hadoop
- GCP
- subdag
- BigQuery
- 공분산
- 유튜브 API
- top_k
- Today
- Total
데이터과학 삼학년
Isolation Forest (for anomaly detection) 본문
Isolation Forest
- Tree를 이용한 이상탐지를 위한 비지도학습 알고리즘
- Regression Decision Tree를 기반으로 실행
- Regression Tree 가 재귀 이진 분할을 이용하여 영역을 나누는 개념을 이용함
-
Random forest와 같이 feature를 random하게 선택함
-
선택된 feature의 maximum, minimum 값 사이의 split value를 이용해 tree 구현
Isolation Forest 구현 개념
- 일반적으로 정상 데이터의 경우, 더 많은 재귀 이진분할이 필요함. 반면에 비정상 데이터는 정상데이터에 비해 이진 분할이 덜 필요하게 된다는 개념에 착안하여 Tree로부터 anomaly를 판단하는 개념 → 예외는 정상에 비해 분리하기가 더 쉽다
(재귀 이진분할이기 때문에 tree의 깊이(or path) 가 짧을 수록 비정상 데이터일 가능성이 높음)
- 아래 그림을 보면 왼쪽그림(정상 데이터) 보다 오른쪽 그림(비정상 데이터)에서 더 적은 분할 수로 나눠진 영역에 anomaly data가 있음을 알 수 있음
-
비정상 데이터가 고립되려면, root node와 가까운 depth를 가짐
-
정상 데이터가 고립되려면, tree의 말단노드에 가까운 depth를 가짐

Isolation Forest Score 산정 방법
- Isolation Tree를 여러개의 앙상블 모델을 만들면 이상지수 score를 계산할 수 있음
-
score는 0~1사이의 값으로 표현
-
Tree는 50~100개 정도의 모델을 사용하면 score가 안정화 된다는 논문이 있음

- score 계산 방법

-
h(x) : x 까지의 경로 길이
-
c(n) : 평균 경로 길이
-
n : the number of external nodes
- c(m)

-
Binary Search Tree (BST) 와 동일한 구조를 가지고 있어, BST 방식으로 경로길이를 탐색함
-
n : 테스트 데이터 수
-
m : 샘플 데이터 수

: harmonic number (

is the Euler-Mascheroni constant.)
- 비정상 판단 유무 (score를 이용)
-
score가 1에 가까우면 비정상 anomaly
-
score가 0.5 이하이면 정상데이터로 판단함
-
만약 모든 score가 0.5에 가깝다면 전체 데이터에서 이상치를 발견하지 못한것으로 간주할 수 있음
Isolation Forest 특징
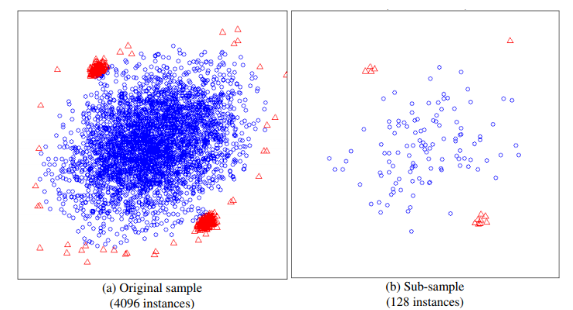
- Sub-sampling : 전수 데이터가 아닌 sampling한 데이터로 모델을 생성 (군집화 이상탐지 방식은 전수데이터를 사용해야 함)
- Swamping : 이상치가 정상치와 가까이 위치된 경우 잘못 분류하게 되는 현상 → 이를 해결하기 위한 해결책은 sub sampling 포인트를 줄이는 것
- Masking : 이상치가 군집화되어 있어 정상치로 잘못 분류하게 되는 현상 → sub sampling으로 해결 가능
- High Dimensional Data : 고차원의 데이터 (feature 가 매우 많은 경우)에서 잘 작동하지 않을 수 있음. 이유는 고차원의 데이터로 넘어갈때 데이터간 sparse한 space가 많이 늘어나기 때문에 split 을 제대로 못할 것임. → 차원을 줄이는 방법 (상관관계, 첨도 확인 등)
- Normal Instances Only : train 데이터에 이상치가 포함되지 않아도 iForest는 잘 작동함. 이유는 score 판정 자체가 path length인 h(x)로 산정하기 때문 → 즉, iForest의 성능에는 이상치가 학습데이터에 있는지 없는지는 중요하지 않음
Isolation Forest 간단 적용 코드
import numpy as np
import pandas as pd
import scipy
from sklearn.ensemble import IsolationForest
mat = scipy.io.loadmat('cover.mat')
X = pd.DataFrame(mat['X'])
y = pd.Series([x[0] for x in mat['y']])
# define % of anomalies
anomalies_ratio = 0.009
if_sk = IsolationForest(n_estimators = 100,
max_samples = 256,
contamination = anomalies_ratio,
behaviour= " new",
random_state = np.random.RandomState(42))
if_sk.fit(X)
y_pred = if_sk.predict(X)
y_pred = [1 if x == -1 else 0 for x in y_pred]- sklearn에서 predict를 한 결과는 이상치 -1, 정상치 1로 반환하여 리턴하고 있음
--> score를 0.5를 기준으로 이상치, 정상치로 나누는 것으로 보임
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
- score_samples 이라는 메서드로 직접 score값을 확인할 수 있음
Isolation Forest 외 타 알고리즘
- Local Outlier Factor : local density deviation을 이용하여 낮은 density를 갖는 샘플을 찾는 기법 (k-means cluster 와 유사한 방식)
Isolation Forest 트리 도식화
from sklearn.tree import export_graphviz
model = clf.estimators_[3]
# .dot 파일로 export 해줍니다
export_graphviz(model, out_file='tree.dot')
# 생성된 .dot 파일을 .png로 변환
from subprocess import call
call(['dot', '-Tpng', 'tree.dot', '-o', 'iForest-tree.png', '-Gdpi=600'])
# jupyter notebook에서 .png 직접 출력
from IPython.display import Image
Image(filename = 'iForest-tree.png')
References
https://en.wikipedia.org/wiki/Isolation_forest
Isolation forest - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Algorithm for anomaly detection Isolation forest is an unsupervised learning algorithm for anomaly detection that works on the principle of isolating anomalies,[1] instead of the most
en.wikipedia.org
https://towardsdatascience.com/outlier-detection-with-isolation-forest-3d190448d45e
Outlier Detection with Isolation Forest
Learn how to efficiently detect outliers!
towardsdatascience.com
https://towardsdatascience.com/outlier-detection-with-extended-isolation-forest-1e248a3fe97b
Outlier Detection with Extended Isolation Forest
Learn what are the latest improvements of a popular outlier detection algorithm
towardsdatascience.com
https://donghwa-kim.github.io/iforest.html
Isolation Forest
Isolation Forest Regression tree기반의 split으로 모든 데이터 관측치를 고립시키는 방법 비정상 데이터가 고립되려면, root node와 가까운 depth를 가짐 정상 데이터가 고립되려면, tree의 말단노드에 가까운 depth를 가짐 특정 한 개체가 isolation 되는 leaf 노드(terminal node)까지의 거리를 outlier score로 정의 그 평균거리(depth)가 짧을 수록 outlier score는 높아짐
donghwa-kim.github.io
'Machine Learning' 카테고리의 다른 글
| Image Classification (Linear, DNN, CNN) (0) | 2020.06.02 |
|---|---|
| Graph 기초 (0) | 2020.06.02 |
| Image classification (Linear, DNN, CNN) (0) | 2020.03.04 |
| ROC, AUC (0) | 2020.02.17 |
| Mutual Information_ 클러스터링 평가 척도 (1) | 2020.02.14 |


