
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 상관관계
- Retry
- 공분산
- airflow subdag
- Counterfactual Explanations
- grad-cam
- GCP
- Airflow
- flask
- login crawling
- chatGPT
- API
- 유튜브 API
- BigQuery
- youtube data
- hadoop
- tensorflow text
- requests
- XAI
- correlation
- TensorFlow
- top_k
- spark udf
- UDF
- GenericGBQException
- API Gateway
- gather_nd
- integrated gradient
- subdag
- session 유지
- Today
- Total
데이터과학 삼학년
Dataflow SQL 본문
Dataflow SQL
-
GCP Bigquery UI에서 쿼리를 사용하여 Dataflow job을 생성하고 실행시킬 수 있음
-
Dataflow SQL은 Apache Beam SQL 지원
-
Zeta SQL 쿼리 구문 지원
-
BQ UI로 스트리밍 파이프라인 개발 가능
-
스트리밍 데이터 와 일반 데이터 셋의 조인 가능
-
스키마를 일반 테이블, GCS 파일, pub/sub 과 연결하여 데이터 세트를 구성하여 쿼리 실행 가능
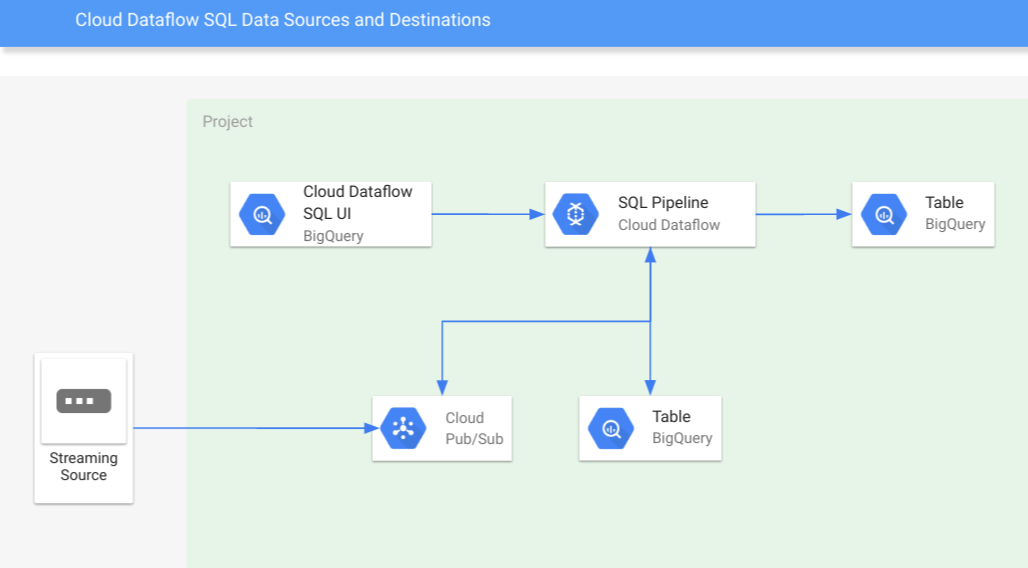
-
주 사용용도는 bigquery table에 있는 data뿐만 아니라, GCS에 있는 데이터, pub/sub으로 스트리밍으로 들어오는 데이터를 처리하는 용도로 사용
사용예시
-
biquery ui에서 옵션에서 cloud dataflow 엔진을 선택하고 쿼리를 날리는 방식으로 실행

-
데이터를 불러올때 FROM 절에 써줘야하는 양식
-
pub/sub 데이터
-
pubsub.topic.project-id.topic-name
-
-
biquery 테이블
-
bigquery.table.project-id.my_dataset.my_table
-
-
cloud storage 데이터
-
GCS 에서 데이터를 dataflow에 사용하려면 먼저 data catalog를 만들어야함
-
Cloud Storage 파일 세트를 관리할 항목 그룹 만듦
-
-
data catalog 설정방법
gcloud beta data-catalog entry-groups create Entry_group_name --location=Region
-
파일세트를 항목그룹에 배치
gcloud beta data-catalog entries create Fileset_name
--entry-group=Entry_group_name \
--location=Region \
--gcs-file-patterns=gs://my-bucket/*.csv \
--description="Fileset_description" \
-
data catalog를 모두 만들었으면, bigquery에서는 아래와 같이 데이터 셋을 불러와 활용함
-
datacatalog.Project_ID.Region.Entry_group.Fileset_name
-
-
위의 세팅이 완성되면 Bigquery ui에 작업할 쿼리를 작성
|
WITH log_A AS ( SELECT * FROM datacatalog.`us-central1`.`my-fileset-group`.`daily.registrations` ), log_B AS ( SELECT tr.*, sr.sales_region FROM pubsub.topic.`project-id`.transactions AS tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_dataset.us_state_salesregions AS sr ON tr.state = sr.state_code ) SELECT * FROM log_A LEFT JOIN log_B USING (sales_region) |
-
쿼리를 작성한 후 Cloud Dataflow 작업 만들기를 누른후 설정값 입력

-
설정값에서 Dataflow를 통해 작업한 결과들을 어디에 쌓을 지 지정함
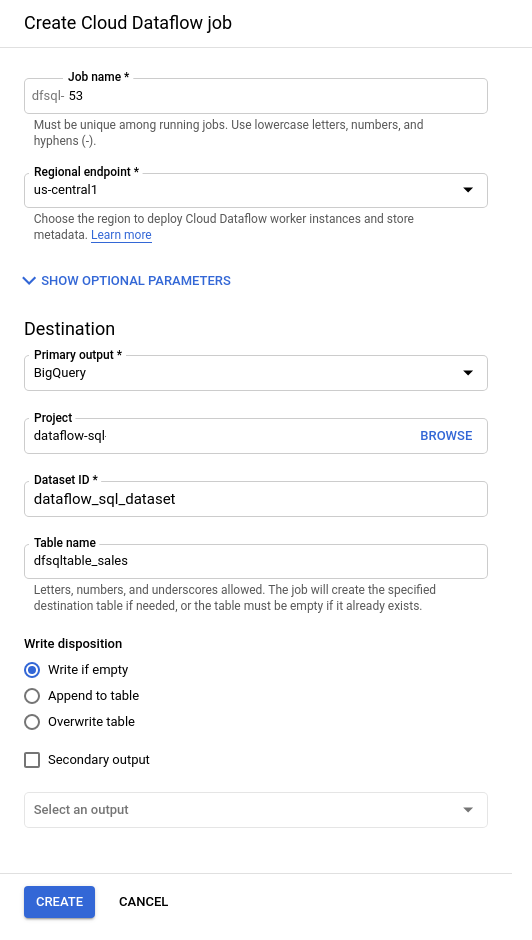
-
create를 누르고 나서 Dataflow ui로 가면 파이프라인을 볼 수 있음
-
예시(pub/sub, biquery table 만 가지고 데이터 join 합친 예제)
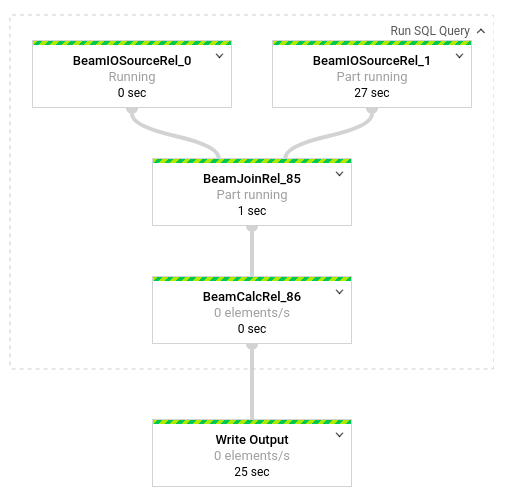
-
pub/sub 데이터의 경우는 스트리밍되는 시간 간격에 따라 데이터를 유동적으로 처리할 수 있음
|
SELECT sr.sales_region, TUMBLE_START("INTERVAL 15 SECOND") AS period_start, SUM(tr.amount) as amount FROM pubsub.topic.`project-id`.transactions AS tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_dataset.us_state_salesregions AS sr ON tr.state = sr.state_code GROUP BY sr.sales_region, TUMBLE(tr.event_timestamp, "INTERVAL 15 SECOND") |
Limits
-
가능한 리소스 : Pub/Sub, Cloud Storage 파일, BigQuery 테이블
-
pub/sub 데이터는 json 형식이어야 함
-
데이터의 타임스탬프 최소 단위는 1ms로, 이 이하인 경우, 밀리초 단위로 자름
-
GCS의 csv파일 header를 인식하지 못함(header 열이름없이 데이터만 있어야함)
References
-
https://medium.com/google-cloud/google-cloud-platform-for-sql-practitioners-2b2e4507535e
-
https://cloud.google.com/dataflow/docs/guides/sql/dataflow-sql-ui-walkthrough (실습)
'GCP' 카테고리의 다른 글
| Cloud Natural Language API (GCP) (0) | 2020.06.01 |
|---|---|
| AutoML Natural Language 소개 (0) | 2020.05.22 |
| GCP AI-platform Stream Logs error (1) | 2020.02.22 |
| Bigquery Table_Suffix 관련 error(적재되는 data type이 꼬였을 때) (0) | 2020.01.30 |
| Data_analysis on GCP (0) | 2020.01.17 |



