
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- API
- youtube data
- GenericGBQException
- Airflow
- subdag
- Counterfactual Explanations
- correlation
- flask
- TensorFlow
- chatGPT
- spark udf
- gather_nd
- BigQuery
- GCP
- 공분산
- API Gateway
- UDF
- tensorflow text
- integrated gradient
- 상관관계
- session 유지
- hadoop
- airflow subdag
- grad-cam
- 유튜브 API
- login crawling
- XAI
- Retry
- requests
- top_k
- Today
- Total
데이터과학 삼학년
CopyOnWrite VS MergeOnRead 본문
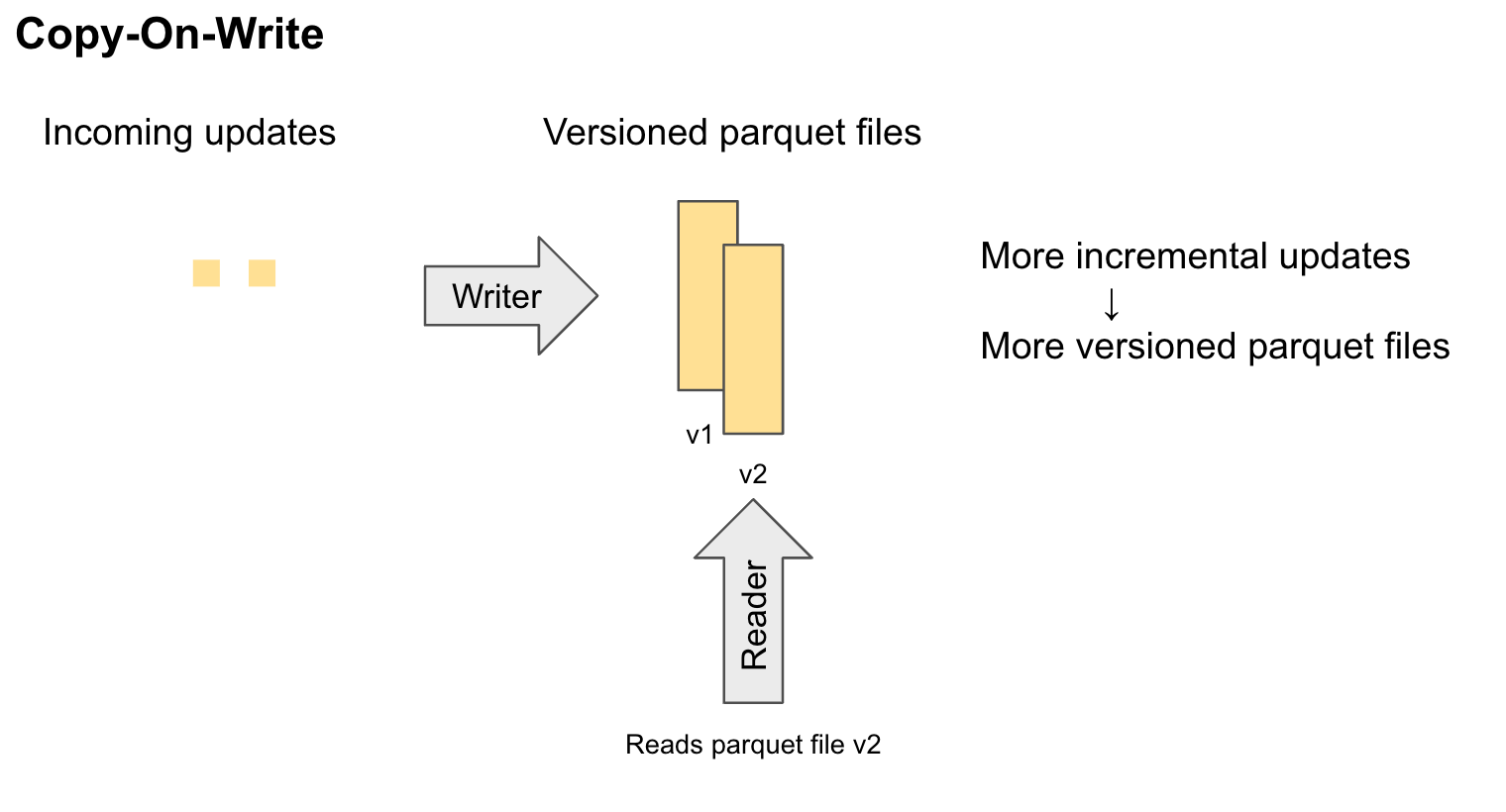
Copy On Write
- 쓸 때 데이터를 병합 → 쓰기 성능은 떨어지지만 읽기 성능은 더 높음
- 변경데이터에 대해서 batch로 처리
- 데이터를 합쳐서 하나의 parquet 파일을 생성
>> 새로운 데이터가 유입될때 기존 데이터를 copy하고 새로운 데이터를 추가하여 새로운 version의 데이터를 만듦
Merge On Read
- 읽기 중에 병합을 수행하여 읽기 성능을 확인 → 데이터를 적시에 쓰기 때문에,거의 실시간 데이터 분석 기능을 제공할 수 있음
- 변경데이터에 대해서 실시간으로 처리
- 변경분 데이터에 대해서는 avro로 저장
- 1분단위 commit
- 5분단위 data compaction 을 하고 해당파일이 base file(parquet)로 됨
- 사용자에게 ReadOptimized (RO) Table(실시간 반영안됨) 과 Near-Realtime (RT) table(실시간 반영된 테이블)을 제공
>> 새로운 데이터가 유입될때 기존 데이터를 유지하고 변경데이터는 그대로 유지하여 가지고 있다가, 읽을때 기존버전에 새로운 데이터를 반영하는 merge(compaction)과정을 거쳐 새로운 버전의 데이터를 생성하여 읽음

CopyOnWrite VS MergeOnRead
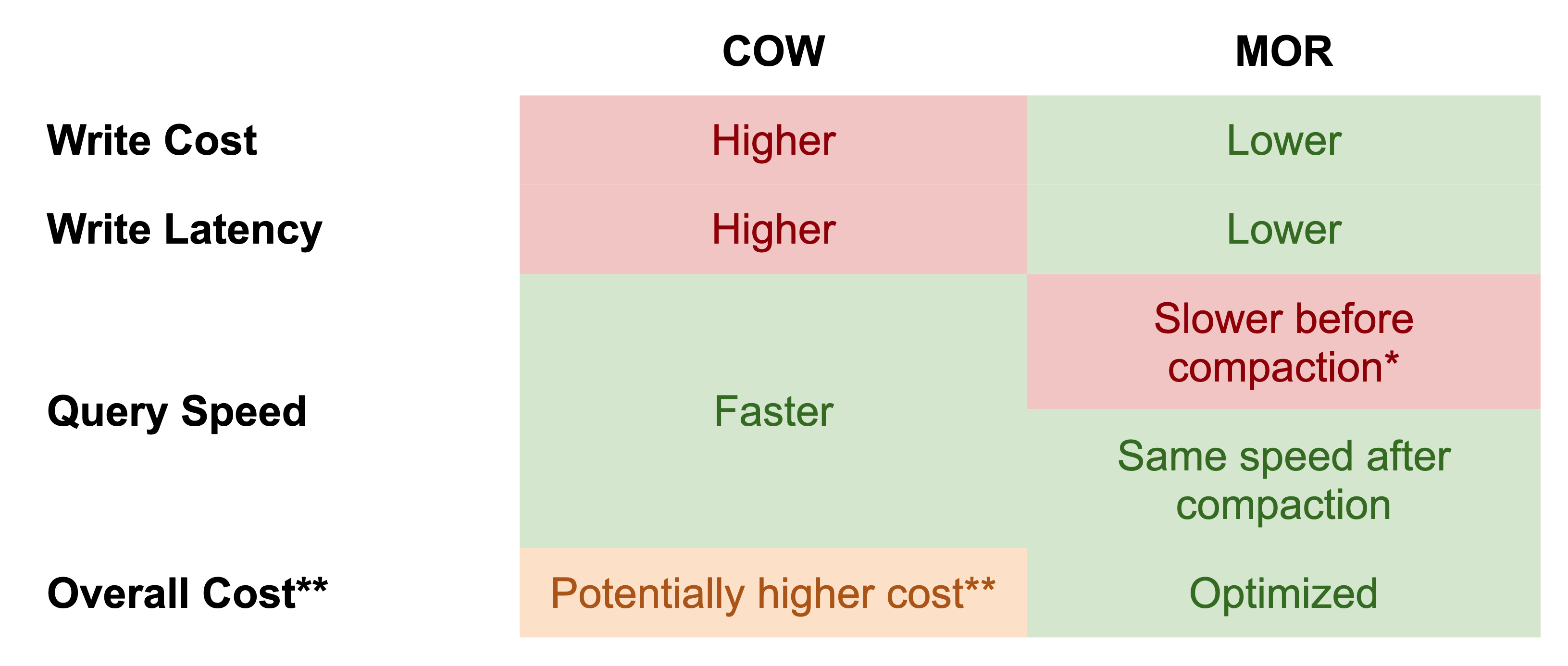
참고
Comparing Apache Hudi's MOR and COW Tables: Use Cases from Uber and Shopee
This post outlines Apache Hudi’s two table types: Copy-on-Write and Merge-on-Read. You’ll understand the use cases for each table type with real-world examples from Uber and Shopee.
www.onehouse.ai
'Data Visualization & DataBase' 카테고리의 다른 글
| [DE] 데이터 파티셔닝 & 샤딩 (0) | 2023.08.07 |
|---|---|
| ODS(Operational Data Store), 팩트 테이블, 디멘션 테이블 (0) | 2023.05.29 |
| [Impala] with 문(clause) 결과셋을 임의 저장하지 않음 (0) | 2023.02.13 |
| [DB] overwrite VS upsert (0) | 2022.12.06 |
| [DB] JOIN condition에 OR 포함? (0) | 2022.11.26 |


