
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- session 유지
- chatGPT
- 유튜브 API
- 상관관계
- airflow subdag
- correlation
- requests
- spark udf
- login crawling
- flask
- UDF
- GenericGBQException
- TensorFlow
- BigQuery
- integrated gradient
- API
- 공분산
- tensorflow text
- subdag
- XAI
- grad-cam
- youtube data
- gather_nd
- Retry
- hadoop
- Airflow
- GCP
- top_k
- API Gateway
- Counterfactual Explanations
- Today
- Total
데이터과학 삼학년
Data_analysis on GCP 본문
GCP for data analytics
-
Infra에 신경쓰지 말고, Query에만 집중할 수 있음
-
빠른 연산 속도
-
Elastic하게 상황에 따라 vm을 조절(Auto scalability)
Big Data Tools
-
Data 분석가가 data의 수집단계(ingest)에서 부터 참여하여 원하는 데이터(형태)를 수집하는 것이 중요
-
Ingest -> Bigquery storage
-
Transform -> Dataflow, Dataprep
-
Store -> Cloud storage
-
Analyze -> Bigquery alysis(SQL), Datalab
-
Visualize -> data studio
-
BigQuery
-
Petabyte scale 감당
-
접근 권한 부여에 따른 보안
SQL In BigQuery
-
Datalab(주피터환경)에서 쿼리를 날려서 작업이 가능
-
Query : mySQL 구문 지원
-
FROM -> SELECT -> WHERE 순으로 질의 처리
-
Query 도움말
-
CAST( ‘12345’ AS INT64)
-
CAST( ‘12345’ AS STRING)
-
-
SELECT FROM WHERE GROUP BY HAVING ORDER BY LIMIT
-
FROM 절에서는 `project.dataset.table` (not ‘)를 사용(탭키 위 문자, backtab)
-
FORMATTING은 맨 마지막에 하는 것 추천
-
String은 ‘ ’ 사용
-
Distinct : 중복 제거
-
Round(revenue, 2) : 소수점 둘째자리까지 표현(반올림)
-
Group by에 쓸 column은 반드시 select 구문에 포함되어야 함
-
드래그 쿼리 실행 단축키 : ctrl + e
-
WHERE LOWER(name) LIKE ‘%help%’
-
CAST : data type 변경
-
CONCAT(‘12345’,’678’) => ‘12345678’
-
REGEXP_CONTAINS("Lunchbox",r"^*box$") => true
-
ENDS_WITH("Apple","e") => true
-
LOWER("Apple") => "apple"
-
Consistent data : data의 관계...어떤 데이터가 True이냐, 혹은 inconsistent한 데이터의 정보가 모두 True는 아닌가 확인
-
Uniformity : 단위
Dataprep
-
Dataprep을 이용하여 간단한 전처리 및 join으로 data preprocessing 가능
-
작은 데이터 셋으로 test 후 production하는 것 추천
SQL 권한관리
-
VIEW에 대한 접근 제한
Bigquery
- 1. Union
-
데이터 셋 붙이기(아래로)
-
Union distinct : 중복을 제거하며 붙여줌
-
FROM `project.dataset.table*` => table1929, table1930 등 table 이하의 모든 데이터를 붙여줌
-
WHERE _TABLE_SUFFIX > ‘1950’ 을 쓰면 * 표시한 전체 데이터 중 1950년 이상만 가져옴
|
#standardSQL SELECT stn, wban, temp, year FROM `bigquery-public-data.noaa_gsod.gsod1929` UNION DISTINCT `bigquery-public-data.noaa_gsod.gsod1930` UNION DISTINCT `bigquery-public-data.noaa_gsod.gsod1931` UNION DISTINCT `bigquery-public-data.noaa_gsod.gsod1932` # This is getting out of hand |
#standardSQL SELECT stn, wban, temp, year FROM `bigquery-public-data.noaa_gsod.gsod*` # All gsod tables |
|
#standardSQL SELECT stn, wban, temp, year FROM `bigquery-public-data.noaa_gsod.gsod*` # All gsod tables after 1950 WHERE _TABLE_SUFFIX > '1950' |
-
2. Join
-
Table 간 key를 중심으로 Join
-
Inner join, full join, left join, right join 모두 지원


- 3. Advanced Functions and Clauses
-
APPROX_COUNT_DISTINCT : data의 row 숫자를 파악하고 싶을 때 사용
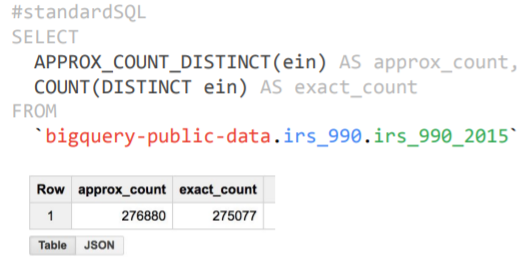

-
WITH 문
-
WITH를 이용하여 하나의 새로운 데이터셋을 구성한 후 쿼리작성 -> 네스티드 셀렉트를 안해도 되는 이점이 있음
-
_TABLE_SUFFIX : * 값을 의미함
-
Ex. FROM `bigquery-public-data.irs_990.irs_990_2*` 이면 _TABLE_SUFFIX 는 015,016,012 등 임
|
#standardSQL #CTEs WITH # 2015 filings joined with organization details irs_990_2015_ein AS ( SELECT * FROM `bigquery-public-data.irs_990.irs_990_2015` JOIN `bigquery-public-data.irs_990.irs_990_ein` USING (ein) ), # duplicate EINs in organization details duplicates AS ( SELECT ein AS ein, COUNT(ein) AS ein_count FROM irs_990_2015_ein GROUP BY ein HAVING ein_count > 1 ) |
-
Bigquery의 Schema Design
-
Table 안에 다시 Table을 넣어 놓은 형태_Nested schemas structure

-
SELECT [a,b,c,d] AS fruit
|
row |
fruit |
|
1 |
a |
|
b |
|
|
c |
|
|
d |
-
UNNEST -> NEST를 해제시키는 함수

-
STRUCT

-
Optimizing
-
Low-cardinality로 group by 사용
-
Union 사용시는 _TABLE_SUFFIX 를 이용하여 효율적으로 작성
-
Self-join은 지양
-
Datalab을 이용하여 작성하는것
-
Datalab
-
코드 창에 %%sql or %%bq 입력후 쿼리 작성하면 바로 실행할 수 있음
'GCP' 카테고리의 다른 글
| GCP AI-platform Stream Logs error (0) | 2020.02.22 |
|---|---|
| Bigquery Table_Suffix 관련 error(적재되는 data type이 꼬였을 때) (0) | 2020.01.30 |
| Data engineering on GCP (0) | 2020.01.17 |
| Kubeflow pipeline (0) | 2020.01.09 |
| Bigquery load error (GenericGBQException)_(동시접근, parallel 작업시) (0) | 2020.01.09 |


