Feature Interaction
Feature Interaction
- Feature간의 상호작용의 정도를, partial dependance value를 기반으로 추정하는 방식
- "전체는 부분의 합보다 크다" 라는 아리스토텔레스의 말에서 얻은 아이디어일까?
- 쉽게 예시로 설명해보면
feature A, B가 있다고 하자.
Feature A = 10, Feature B = 5 일때, Feature A + Feature B = 15라고 예측할수 있지만,
실제 Feature A + Feature B = 20이다.
이 현상을 통해 우리는 Feature A와 Feature B는 서로 같이 쓰일때 +5의 상호작용 효과가 있다고 추론할 수 있다는 개념
Friedman의 H-statistics
- Feature Interaction을 수치로 구하기 위해 나온 개념
- 0과 1사이의 값을 가지며, 1에 가까울 수록 큰 상호작용을 가지고 있음을 의미함
- 구하는 방식은 partial dependance function을 통해 decompose하고 예측값이랑 비교해서 더하고 빼고 하는...아주 생각보다 이해하기 싫은 수식이 많이 쓰여있음..
(R 패키지에서 지원해준다니 가져다 쓰면 될듯, scikit-learn에도 있다는 소리를 들은 것 같음)

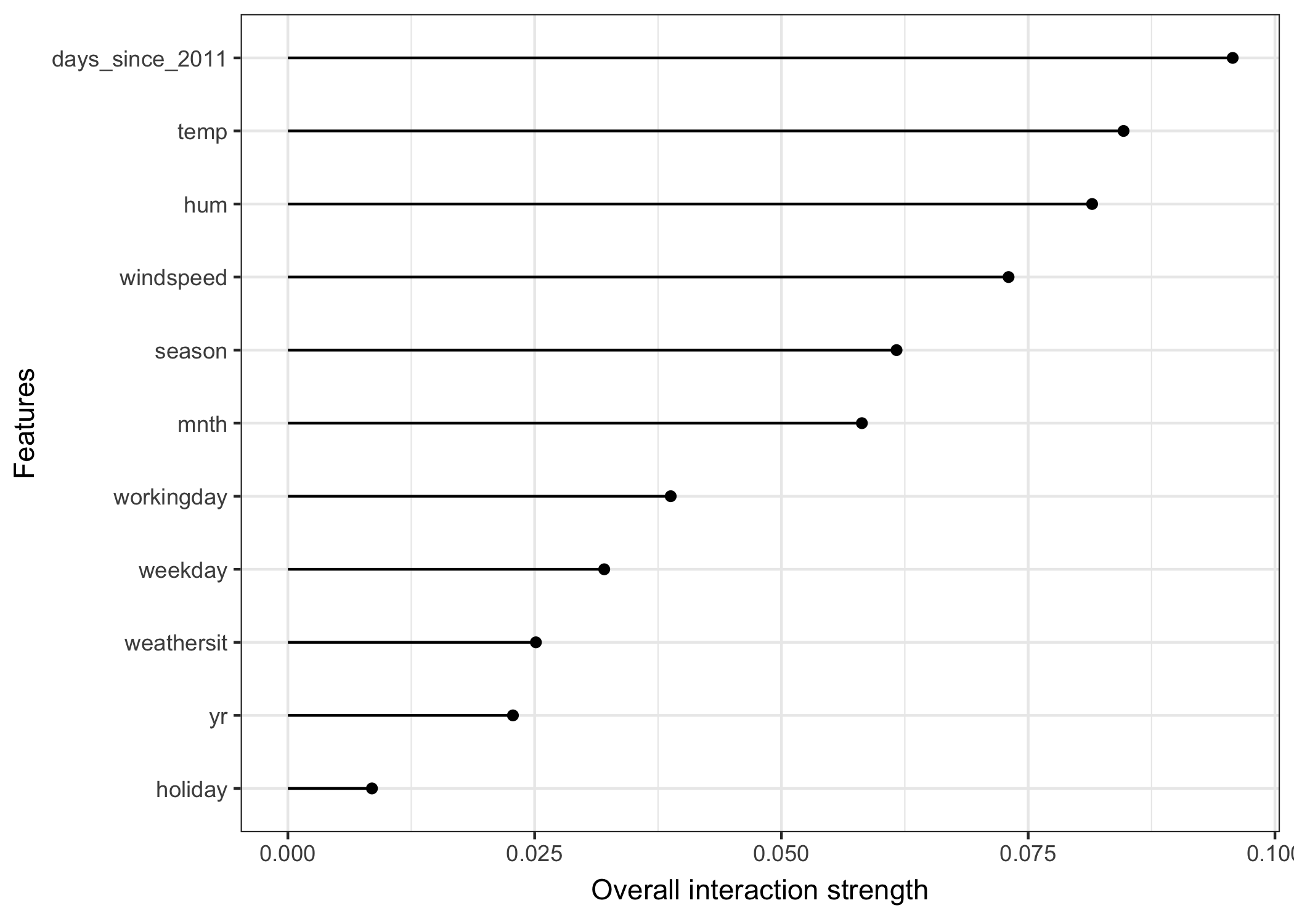
예시
- 자전거 렌트 횟수와 각 Feature간 상호작용효과를 확인한 것으로, 각 feature에 큰 상호작용은 없는 것으로 보임
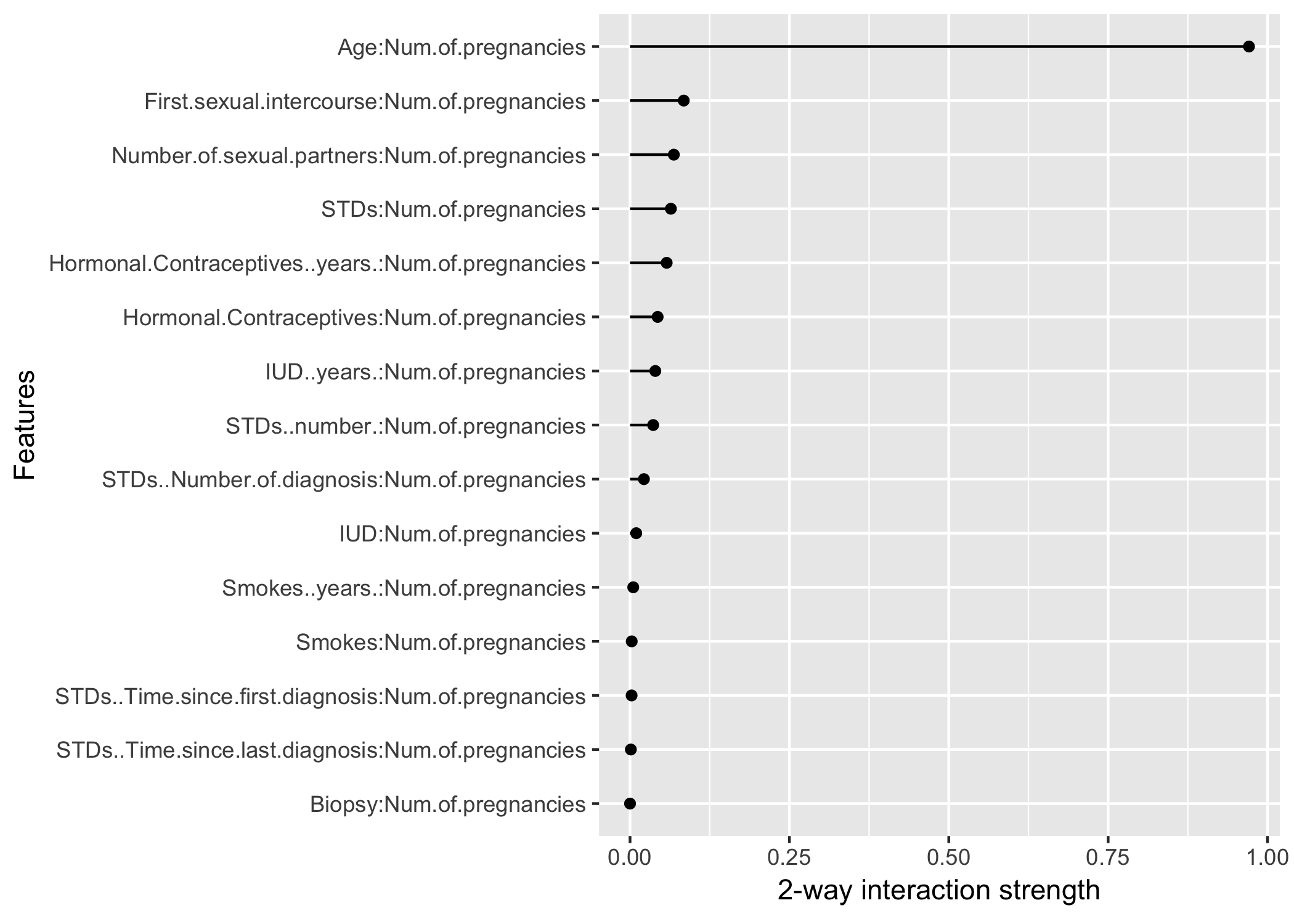
- 2-way interaction으로 나이와 임신횟수가 상호작용 효과가 크다는 것을 나타내는 그림
ㄴ 2-way는 feature수 Combination 2 의 연산횟수를 가져 연산에 오랜시간이 소요될 수 있음
장점 / 단점
- 항상 0 과 1 사이 이기 때문에 기능 간에는 물론 모델 간에도 비교 가능
-H-statistic을 사용하면 3개 이상의 Feature 간의 상호 작용 비교 가능
- H-statistic은 계산 비용이 많이 들기 때문에 계산하는 데 오랜 시간이 걸림
- 때로는 결과가 이상하고 예상한 결과가 나오지 않음
- 독립적으로 섞을 수 있다는 가정하에 작동합니다(부분 의존도 플롯과 동일한 문제). feature간 강한 상관관계가 있으면 가정이 위반
참조