GCP
[Bigquery client] BQ client를 이용하여 dataframe 의 array 데이터 빅쿼리에 올리기
Dan-k
2020. 8. 28. 21:41
반응형
제곧내
pandas 작업을 하다보면 한 column에 array형태가 들어가는 케이스가 있다.
이를 bigquery에 로드하면 bigquery는 array 자체를 string으로 받아 버리는 문제가 있다.
즉 내가 원하는 형태는
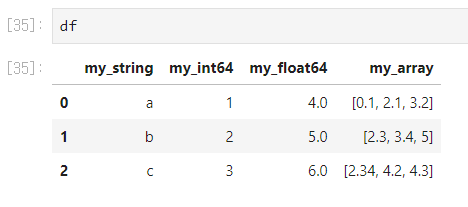
이런 pandas dataframe 자료가 있을 때

이것을 Bigquery에 그냥 올리면 아래와 같이 string 형태로 올라가지만

실제 원하는 케이스는 아래 그림과 같을 것이다.

자 코드를 통해 어떻게 하는지 알아보자.
bigquery에 table을 load하기 위해서는 일단 bigquery client api를 사용한다.
from google.cloud import bigquery
import pandas
client = bigquery.Client()
## data
df = pd.DataFrame(
{
'my_string': ['a', 'b', 'c'],
'my_int64': [1, 2, 3],
'my_float64': [4.0, 5.0, 6.0],
'my_array' : [[0.1, 2.1, 3.2],[2.3, 3.4, 5],[2.34, 4.2, 4.3]]
}
)
ARRAY를 BQ 에 올리기 위해서는 schema 타입에 mode를 사용하여 mode가 REPEATED가 되게 해주어야한다
그러나, REPEATED를 사용할 경우 JSON 파일만 지원하기 때문에 data인 dataframe을 record 형태의 json 파일로 변형해 준다
def json_from_df(df):
result = df.to_json(orient="records")
parsed = json.loads(result)
return parsed
data = json_from_df(df)
data
###
[{'my_string': 'a',
'my_int64': 1,
'my_float64': 4.0,
'my_array': [0.1, 2.1, 3.2]},
{'my_string': 'b',
'my_int64': 2,
'my_float64': 5.0,
'my_array': [2.3, 3.4, 5]},
{'my_string': 'c',
'my_int64': 3,
'my_float64': 6.0,
'my_array': [2.34, 4.2, 4.3]}]빅쿼리에 table을 로드하기 위해 스키마, append, replace 할지 등의 config 설정을 해준다
schema = [
bigquery.SchemaField("my_string", "STRING"),
bigquery.SchemaField("my_int64", "INTEGER"),
bigquery.SchemaField("my_float64", "FLOAT"),
bigquery.SchemaField("my_array", "FLOAT", mode="REPEATED")
]
job_config = bigquery.LoadJobConfig(schema=schema, write_disposition='WRITE_APPEND') # replace : WRITE_TRUNCATE
마지막으로 로드할 TABLE 위치 (프로젝트.데이터셋.테이블명)을 입력해주면 끝
bqclient.load_table_from_json(data, destination_table, job_config=job_config).result()
728x90
반응형
LIST