LIME (Local Interpretable Model-agnostic Explanation)
LIME (Local Interpretable Model-agnostic Explanation)
Global vs Local Surrogate Analysis
- Global Surrogate Analysis
학습 데이터(일부 또는 전체)를 사용해 대리 분석 모델을 구축하는 것 - Local Surrogate Analysis학습 데이터 하나를 해석하는 과정
LIME 간략한 개념 및 소개
- LIME : 국지적(local) 단위의 모델을 설명하는 기법
- LIME은 개별 예측의 결과를 설명하기 위해 training local surrogate models에 초점을 맞춤
- 일반적인 intepretable 모델 처럼 모델의 가중치에 신경써서 모델을 해석하는 방법이 아니라 휴리스틱한 방법으로 Black box model에 input 데이터를 넣고 그 결과를 가지고 해석
- input 데이터를 LIME 알고리즘에 맞게 변형한 데이터를 Black box model에 여러차례 넣어봄으로써 리턴되는 결과를 가지고 해석하는 방법
- 해당 방법은 결국 모델이 왜 이런 결과를 냈냐에 집중하는 것이기 때문에 목적에 잘 부합하는 방식이라 볼 수 있음
- 수리적으로 Local Surrogate 모델은 아래 식으로 표현할 수 있음
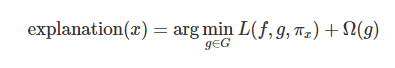
- 여기서, explanation x는 설명하고자하는 input x 값에 대한 설명으, L은 loss를 의미하며, 이는 original model의 결과와 추정에 사용되는 모델 사이의 loss를 의미, 파이x는 x 주변의 데이터를 어느정도까지 고려할 지를 결정, 옴(g) : model complexity 정도를 의미함
- 즉, 파이 x를 통해 local의 영역을 설정한다고 생각해도 됨
LIME 의 Training step
- Black box model에서 예측결과를 설명하기 원하는 input X 설정
- Black box model을 해석하기 위한 Dataset을 생성
- 모델 해석을 위해 새로 만든 sample 들의 weight 계산하기
- weighted sample을 학습, interpretable model 구성
- local model을 해석하기위한 결과를 설명하기
LIME 의 특성
- Feature 수 K가 적을 수록 해석이 더 용이함
- Model 해석을 위한 data 생성 방법은 data의 type에 따라 다르게 적용됨
- tabular
- text
- image
LIME for Tabular Data
- Tabular data는 가장 일반적인 dataset으로 시각화를 이용하여 설명하기에 매우 유용함

- LIME Algorithm for tabular data
- Random Forest 모델을 이용한 결과를 뿌림(Feature X1, X2 가정)
- dark 1, Light 0
- 설명을 할 예측 data set을 큰 점으로 찍음, 그리고 그 점을 기준으로 normal distribution을 이용해 sample data를 만듦
- 설명을 위해 예측할 data와 가까운 sample들에 높음 weight를 매김
- weighted sample로 부터 locally learned model을 만들어 classification을 grid로 표현
- LIME 알고리즘에서 가장 중요한 것이 설명할 예측 데이터 주변에 weight를 주는것임
- weight을 주는 것은 neighborhood를 지정하는 것을 말하는데 LIME 에서는 exponential smoothing을 이용해 가까운 점에는 높은 가중치, 먼 점에는 낮은 가중치를 매김

- smoothing kernel을 지정하는데 있어 어려운 것은 kernel width를 지정하는 것인데 kernel width는 얼마나 많은 neighborhood를 볼지 결정하기 때문에 매우 중요
- 일반적으로 kernel width는 0.75 * 루트(feature 수) 를 이용함
- 여전히 best kernel과 kerner width를 정하는 것은 어려움 (hp tunes)
- kernel width에 따라 예측되는 결과를 비교

- 굵은 선은 black box model의 실제 예측값을 의미함
- 나머지 선은 kernel width에 따라 예측된 local model의 결과를 표현함
- 그림에서 보듯이 feature의 차원이 많아지면 결과는 당연히 더 좋지 않음을 예측할 수 있음
- example
- data : bike rental data
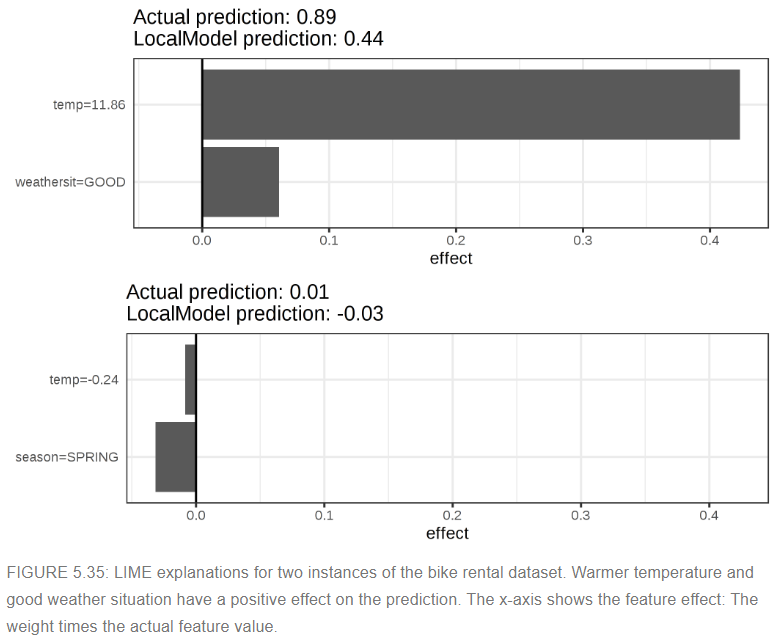
- tree를 100개 가진 random forest로 어떤 날에 bike rental수가 많은지를 측정하는 모델을 만들었을때, 각 feature에 대한 영향력을 위 그림처럼 표현할 수 있음
- 그림에서 보듯이 categorical feature가 numerical feature보다 설명하기 용이함을 알 수 있음
- numerical feature를 bins을 이용하여 categorical feature로 변환하여 분석하는 것도 하나의 solution일 될 수 있음
LIME for Text
- Text data를 분석할때는 모델 해석을 위한 dataset을 구성하는 방법이 tabular data와는 다름
- Text LIME은 dataset을 생성할때 Original TEXT에서 단어(word)를 제거해가며 분석하는 방식으로 dataset을 만듦
- 예를 들면, 아래 표와 같이 각 단어 유무에 따라 1, 0 으로 표시한 data를 만듦

- 여기서, prob은 해당 데이터를 black box model에 넣었을 때의 return된 확률값을 의미함
- weight의 경우, original data에 비해 소실된 데이터의 비율로 weight를 나타냄
- 예를 들어 전체 7단어에서 한단어가 빠진 6단어로 표현했을 때,
weight = 1 - 1/7 로 나타낼 수 있음
- 그리고 이렇게 만들어진 data를 LIME Algoritm에 집어 넣어 아래 표처럼 각 feature weight를 계산하게 됨

- 이런 식으로 나오면 channel이라는 단어가 spam을 구분하는데 큰 weight가 매겨져 있음을 확인할 수 있음
LIME for Images
- Image를 위한 LIME은 tabular, text 데이터와는 또 다르게 데이터셋을 생성시킴
- 일반적으로 각 pixel을 random하게 변형시킬 것이라고 생각하지만 그렇게 하지 않음
- superpixels을 껐다 켰다하는 식으로 데이터를 생성 시킴
- superpixels : pixels 끼리 서로 비슷한 색으로 연결되어 있는 것을 지칭
- superpixels을 끈다는 의미는 superpixel의 값을 사용자가 정의한 값으로 변경 시킴을 의미 (gray)
- Inception v3 model을 이용해 bread를 구분하는 문제가 있다고 하자
- LIME은 위의 그림처럼 label을 판단하는데 영향을 주는 부분을 표시할 수 있음
- 여기서 green은 해당 pixels로 인해 해당 label을 판단하는데 양의 가중을 주는 것을 의미하고, red는 음의 가중을 주는 것을 의미함 (해당 label 이 아님을 증거)
- 위 그림에서 베이글을 예측하는데 그림의 녹색부분이 큰 역할을 했다는 것을 바로 확인할 수 있음

Advantage
- 실무에서 black box model이 성능이 더 좋더라도 예측결과를 설명하기 쉬운 interpretable model을 쓰는 경우가 더 많음 (shallow decision tree, regression model 등)
- 그러나, LIME을 쓰게 되면 black box model의 예측결과에 대한 해석을 추론할 수 있는 장점이 있음
- LIME의 방식은 상당히 Human-friendly한 방식
- LIME은 Tabular, Text, Images 에서 모두 사용할 수 있는 거의 없는 방법 중 하나임
- 특히, embedding한 data와 같이 추상화된 data에도 적용할 수 있음
- 설명하고자하는 data의 output만 가지고 모델을 해석하기 때문
- interpretable model의 경우, model에서 부여된 각 feature의 weight등을 파악하기때문에 추상화된 데이터에서는 부적합함
- ex. PCA에 태운 regression model 은 해석이 어려움
Disadvantage
- data의 neighborhood에 대한 범위를 정의하기 어려움 (tabular 모델 분석)
- kernel setting의 hptune 문제가 있음
- sampling 은 LIME의 결과를 향상시킬 것임 그러나 data는 Gaussian distribution에 의해 sampling 되는데 이는 feature간의 correlation을 무시하게 됨
- 설명 모델의 복잡성이 미리 정의가 되어야함
- This is just a small complaint, because in the end the user always has to define the compromise between fidelity and sparsity.
- 설명력의 불안정성이 큰 문제 → sampling을 계속해서 돌리다보면 돌릴때마다 모델의 설명이 계속 바뀔 것
실험
- 긍정, 부정의견 텍스트 분류 문제


결과 Screenshot

출처
- Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. "Why should I trust you?: Explaining the predictions of any classifier." Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. ACM (2016).↩
- Alvarez-Melis, David, and Tommi S. Jaakkola. "On the robustness of interpretability methods." arXiv preprint arXiv:1806.08049 (2018).↩
- https://github.com/marcotcr/lime
- https://christophm.github.io/interpretable-ml-book/lime.html
5.7 Local Surrogate (LIME) | Interpretable Machine Learning
Machine learning algorithms usually operate as black boxes and it is unclear how they derived a certain decision. This book is a guide for practitioners to make machine learning decisions interpretable.
christophm.github.io
marcotcr/lime
Lime: Explaining the predictions of any machine learning classifier - marcotcr/lime
github.com
https://velog.io/@tobigs_xai/2%EC%A3%BC%EC%B0%A8-SHAP-SHapley-Additive-exPlanation
[2주차] SHAP (SHapley Additive exPlanation)
SHAP (SHapley Additive exPlanation)
velog.io